

 Высшая математика – просто и доступно!
Высшая математика – просто и доступно! Наш форум, библиотека и блог:
Наш форум, библиотека и блог: 


 Повторяем школьный курс
Повторяем школьный курс
 Карта сайта
Карта сайта

Математическая статистика. Начало
Есть правда, есть большая правда, а есть статистика на mathprofi.ru!
На протяжении многих лет я всё думал, когда же доберусь до этой темы, и вот, наконец-то свершилось! …как и во многих делах, самое трудное – первый шаг, но я таки открыл вёрдовский файл (решался и обдумывал 2 недели) и с радостью и даже какой-то торжественностью написал первый абзац.
И сразу второй. Что нужно для изучения математической статистики? Ничего особенного. Нужно уметь складывать, умножать, делить, извлекать корни и ещё много чего выполнять другие бесхитростные действия. Да, вот так просто. Настоящий курс предназначен для начинающих статистиков, и на предстоящих уроках научимся решать типовые задачи, которые реально встречаются в ваших студенческих работах.
Из инструментальных средств потребуется Эксель (не умеете – научим!), проверьте, есть ли он у вас, и калькулятор, лучше оффлайн калькулятор с кнопочками, ибо на зачёте или экзамене гаджетами, как правило, пользоваться нельзя.
Из литературы рекомендую те же две книги: задачник и учебное пособие В.Е. Гмурмана под названием Теория вероятностей и математическая статистика.
Для желающих освоить предметы в максимально короткие сроки, есть pdf-курсы, созданные по материалам сайта, копия тут. Не будем терять времени и здесь – начинаем.
Математическая статистика следует «вторым эшелоном» за теорией вероятностей, и это не случайность, а логическое продолжение. Отличие состоит в том, что теорвер даёт теоретическую оценку случайным событиям, а статистика работает с практическими, или как говорят, эмпирическими данными, которые берутся непосредственно «из жизни». Поэтому для изучения темы желательно (но не критично обязательно) знать азы теории вероятности, в частности, случайные величины – многие понятия и формулы будут очень и очень схожи.
Что такое математическая статистика? Её часто называют то наукой, то разделом математики. И это правда :) Математическая статистика, буду краток, изучает методы сбора и обработки статистической информации для получения научных и практических выводов. Статистическая – это та, которую можно выразить числами. Эта информация появляется в результате исследования массовых (обычно) явлений, которые носят случайный характер.
Причём, информация может носить как количественный характер (например, размеры чего-либо), так и качественную природу – «оцифровать» можно, да хоть пятьдесят оттенков серого.
Немедленный пример. Что главное орудие физика? Секундомер:
Пример 1
Студент Константин выполняет лабораторную работу по определению коэффициента вязкости жидкости методом Стокса.
…тихо-тихо, тут будет всего несколько чисел :)
Экспериментальная часть этой работы состоит в том, что в высокий цилиндрический сосуд с жидкостью сбрасывается достаточно маленький и тяжёлый шарик, после чего замеряется время его погружения.
Время погружения шарика зависит от множества случайных факторов: прямоты рук экспериментатора, погрешности измерения времени, хаотичного движения молекул жидкости и т.д., вплоть до влияния Луны. Поэтому эксперимент целесообразно провести 5-10 раз (как оно обычно и требуется).
Предположим, что в результате 5 опытов получены следующие результаты (в секундах):
![]()
Что произошло? Студент Костя собрал первичные (ещё не обработанные) статистические данные. Они эмпирические (взяты непосредственно из опыта), носят случайный характер (см. выше). И массовый. Ну а как нет? Все однокурсники только и занимаются тем, что бросают в сосуды шарики, да и мало ли на планете похожих шариков, которые тонут в похожей жидкости.
Ну а мы потихоньку погружаемся в терминологию:
- полученные экспериментальные значения называются вариантами, а их совокупность – вариационным рядом. Почему так? Потому что полученные значения варьируются под воздействием случайных факторов.
Справка: вариАнта (существительное женского рода) – в статистике означает отдельно взятое эмпирическое значение.
Далее. Далее Константин должен обработать полученные данные. Во-первых, посмотреть, а нет ли среди полученных значений варианты, которая сильно отличается от всех остальных? Наличие такого значения сигнализирует о том, что соответствующий опыт проведён неудачно и его следует исключить из рассмотрения.
Нет, все значения достаточно близкИ друг к другу, и теперь напрашивается вычислить среднюю величину – разделить сумму значений на их ![]() количество:
количество:
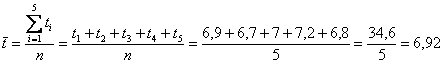 секунды.
секунды.
Это значение называют простой средней или, как многие знают, средним арифметическим. Его стандартно обозначают с чёрточкой наверху.
Справка на всякий случай: математический значок ![]() означает суммирование, а переменная
означает суммирование, а переменная ![]() играет роль «счётчика»; в данном случае
играет роль «счётчика»; в данном случае ![]() изменяется от 1 до 5.
изменяется от 1 до 5.
Если грызут сомнения на счёт точности, то лучше не полениться и провести 10 опытов, что, кстати, удобнее в плане вычислений (на 10 делить проще). И, разумеется, полученный результат будет надёжнее, чем в 1-м случае.
Всё. Статические данные обработаны, осталось сделать выводы. А именно, с помощью значения ![]() вычислить коэффициент вязкости жидкости и ещё там вроде что-то, желающие могут найти эту лабу в Сети.
вычислить коэффициент вязкости жидкости и ещё там вроде что-то, желающие могут найти эту лабу в Сети.
…возможно, у вас возник вопрос, почему я выбрал такой пример? Это единственное, что мне запомнилось из институтского курса физики :)
Пример 2
Студенческая группа сдала коллоквиум по матанализу со следующими результатами:
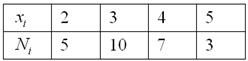
Требуется определить среднюю успеваемость группы
Сбором статистических данных здесь занимался преподаватель, и обратите внимание на их характер: они эмпирические, массовые (громко, конечно, сказано, но таки массовые) и отчасти случайные. Кому-то повезло с вопросом, кому-то нет, кто-то что-то вспомнил / забыл, списал, прогулял и так далее…, прямо какое-то броуновское движение студентов))
Как нетрудно понять, роль вариант ![]() здесь играют полученные оценки, а
здесь играют полученные оценки, а ![]() – это соответствующие частоты – количество студентов, которые получили ту или иную оценку. Подсчитаем общую численность группы:
– это соответствующие частоты – количество студентов, которые получили ту или иную оценку. Подсчитаем общую численность группы:
![]() человек и, привыкаем к терминам, исследуемое множество называют статистической совокупностью, а количество его элементов – объёмом совокупности.
человек и, привыкаем к терминам, исследуемое множество называют статистической совокупностью, а количество его элементов – объёмом совокупности.
Теперь обратим внимание на следующую вещь: двоечников и отличников у нас мало, а нормальных студентов :) много. И возникает вопрос: как вычислить «справедливую» среднюю оценку по всей совокупности? Решение напрашивается – с помощью так называемой средневзвешенной средней:
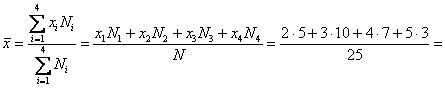
![]() – средняя успеваемость по группе. И я обязательно приму соответствующие меры!
– средняя успеваемость по группе. И я обязательно приму соответствующие меры!
…да, суровые у меня сегодня примеры :) Давайте проанализируем их принципиальные отличия:
1) В первом примере проводится статистическое исследование количественной величины (времени), а во втором «оцифровывается» и анализируется качественный признак (успеваемость).
2) В первом случае исследуемая величина непрерывна, и, строго говоря, все полученные значения различны (отличаются хоть какими-то миллисекундами). Во втором случае варианты дискретны, т.е. представляют собой отдельно взятые изолированные значения. Следует заметить, что они не обязаны быть целыми, так, например, можно ввести в рассмотрение оценки 2,5; 3,5 и 4,5. И у дискретной величины, как правило, есть неоднократно встречающиеся (одинаковые) варианты, так, например, «пятёрка» встретилась 3 раза.
3) В первом примере речь идёт о выборке значений. Что это значит? Это значит, что шарик можно сбрасывать в воду гораздо бОльшее и теоретически вообще бесконечное количество раз. Таким образом, проведённые 5 опытов есть, по сути, выборка, которую называют выборочной совокупностью. При этом соответствующее среднее значение принято называть выборочной средней.
Второй пример отличен тем, что в нём исследуется ВСЯ совокупность, и поэтому её называют генеральной совокупностью, а соответствующее среднее значение – генеральной средней. Но такая ситуация редкость. Редко когда удаётся исследовать всю совокупность.
И сейчас мы подошли к основному методу математической статистики:
Задача
Федор пошёл на базу исследовать помидоры. Требуется определить среднюю массу помидора и среднюю долю первосортных помидоров.
Разбираемся в ситуации. Очевидно, что на базе находится очень и очень много помидоров, обозначим их общее количество через ![]() . Это генеральная совокупность. Для того чтобы решить задачу, можно взвесить каждый овощ:
. Это генеральная совокупность. Для того чтобы решить задачу, можно взвесить каждый овощ: ![]() (в граммах, например) и вычислить генеральную среднюю:
(в граммах, например) и вычислить генеральную среднюю:
![]() – среднюю массу помидора.
– среднюю массу помидора.
Но это долго и трудно, даже если Феде будут помогать все его однокурсники.
Поэтому для оценки параметров генеральной совокупности целесообразно использовать выборочный метод. Его суть состоит в том, что из генеральной совокупности достаточно выбрать ![]() объектов, которые хорошо характеризуют всю совокупность. Это «хорошо» называют представительностью или, как говорят, репрезентативностью выборки. Проговорим это модное слово вслух: ре-пре-зен-та-тив-ность.
объектов, которые хорошо характеризуют всю совокупность. Это «хорошо» называют представительностью или, как говорят, репрезентативностью выборки. Проговорим это модное слово вслух: ре-пре-зен-та-тив-ность.
Что нужно для того, чтобы обеспечить репрезентативность?
Ну, во-первых, выборка должна быть достаточно велика, помидоров так 500-1000 точно, что уже вполне по силам даже одному Феде.
Примечание: в дальнейшем мы сформулируем более строгие статистические критерии на счёт оптимального размера выборки.
Во-вторых, отбор следует осуществлять равномерно – из каждого ящика.
В-третьих, отбор должен быть случайным. Для этого используются разные приёмы, и самый простой здесь – это выбор «вслепую» из случайно выбранного места ящика, обязательно с разной глубины (а то мало ли, что поставщик там мог спрятать).
И, в-четвёртых (а может быть, и, в-первых), есть и другие факторы, которые могут быть менее очевидны. В частности, важно знать, а однородна ли генеральная совокупность? Так, если помидоры поступили от разных поставщиков, то каждую партию полезно исследовать по отдельности (сделать несколько выборок).
Итак, пусть Фёдор по всем правилам выбрал ![]() помидоров, и теперь дело за малым – взвесить каждый овощ:
помидоров, и теперь дело за малым – взвесить каждый овощ: ![]() (граммы) и вычислить выборочную среднюю:
(граммы) и вычислить выборочную среднюю:
![]() – среднюю массу помидора в выборке.
– среднюю массу помидора в выборке.
При этом очевидно, что чем больше объем ![]() выборочной совокупности, тем полученное значение будет точнее приближать генеральную среднюю
выборочной совокупности, тем полученное значение будет точнее приближать генеральную среднюю ![]() .
.
Но фишка состоит в том, что если начать увеличивать выборку в два, три и бОльшее количество раз, то будут получаться выборочные средние, которые мало отличаются от уже рассчитанного значения ![]() . Вы спрОсите, как это установлено? Эмпирически. В результате огромного количества реально проведённых исследований. А затем данный факт был подтверждён и теоретически.
. Вы спрОсите, как это установлено? Эмпирически. В результате огромного количества реально проведённых исследований. А затем данный факт был подтверждён и теоретически.
Таким образом, нет никакого практического смысла тратить силы, время, деньги, нервы на исследование бОльшей выборки и тем более, всей генеральной совокупности.
Вот оно как – в статистике есть и прямая экономическая выгода!
И ещё один момент, чуть не забыл: обратите внимание на используемые буквы – они стандартны. Другие варианты встречаются реже.
Вторая часть задачи. Определим вместе с Фёдором среднюю долю высококачественных помидоров на базе (ну мы же не садисты заставлять его одного заново перебирать 1000 штук :)).
В отличие от первого этапа, здесь мы исследуем уже качественный признак, для которого, тем не менее, можно сформулировать чёткие критерии. Пусть первосортный помидор – это чёрный, лысый красный, спелый, без видимых дефектов, массой выше среднего.
Совершенно понятно, что генеральная совокупность содержит ![]() таких помидоров, и существует точное значение:
таких помидоров, и существует точное значение:
![]() – генеральная доля первосортных помидоров.
– генеральная доля первосортных помидоров.
Но по причине трудозатратности и нецелесообразности полного исследования, достаточно подсчитать количество ![]() таких овощей в выборке и вычислить:
таких овощей в выборке и вычислить:
![]() – выборочную долю, которая будет весьма близка к истинному значению
– выборочную долю, которая будет весьма близка к истинному значению ![]() . Но это только, напомню, при условии грамотно организованной и проведённой выборки.
. Но это только, напомню, при условии грамотно организованной и проведённой выборки.
Доля, как вы догадываетесь, может принимать значение от 0 до 1, и иногда её домножают на 100, чтобы выразить этот показатель в процентах.
Готово.
Константин, Фёдор, спасибо за участие, а остальные, как в том анекдоте, поедут на картошку :) Тем более, сейчас на дворе конец сентября, а осень, как сказал прозаик, это клубни.
В качестве разминки предлагаю вам задачу с тремя пунктами различного уровня сложности. Проверьте наличие инструментов под рукой и свои навыки вычислений (Эксель вечной живой по-прежнему тут):
Пример 3
а) Урожайность картофеля по трём областям за **** год составила 147, 145, 155 ц/га (центнеров с га). Требуется вычислить среднюю урожайность.
Метрическая справка: 1 центнер = 100 кг, 1 тонна = 1000 кг;
1 гектар (га) = 10000 квадратных метров;
показатель ц/га обозначает, сколько центнеров собрано с 1 гектара.
Не забываем приписывать к итоговому результату размерность! (секунды, граммы и т.д., а в данном случае – ц/га).
Вариация чуть сложнее:
б) Известны следующие данные по трём областям:

…это нарисовали чиновники для отчёта – привыкайте к настоящей статистике!:)))
Требуется вычислить среднюю урожайность.
Обратите внимание, что здесь урожайность, скажем, по 3-й области велика, но её посевная площадь мала. Поэтому урожайность уместно «взвесить» по площадям.
и третий пункт, творческий:
в) вычислить среднюю урожайность по следующим данным:

«Валовой» – это значит, всего собрано по области.
ДУМАЕМ, ВНИКАЕМ и РАССУЖДАЕМ – принцип здесь точно такой же, как и при решении задач по теории вероятностей. И, главное, не паримся – это просто разминочные задачи!
Решения с пояснениями и ответы совсем близко.
И в заключение вводного урока систематизируем самое важное:
Математическая статистика – это наука, изучающая методы сбора и обработки статистической информации для получения научных и практических выводов.
Основным методом матстатистики является выборочный метод, его суть состоит в исследовании представительной выборочной совокупности – для достоверной характеристики совокупности генеральной. Данный метод экономит временнЫе, трудовые и материальные затраты, поскольку исследование всей совокупности зачастую затруднено или невозможно.
Для решения задач по математической статистике требуется калькулятор, Эксель и голова. …Нет-нет-нет, голова, разумеется, ещё много где нужна :)
И я желаю вам успехов в дальнейшем освоении курса!
Хотите освоить базовые темы в кратчайшие сроки?
Есть pdf-книга! Ну а если вы учитесь углублённо и / или никуда не торОпитесь, то вперёд, без страха и сомнений:
2. Дискретный вариационный ряд
3. Интервальный вариационный ряд
4. Мода, медиана, генеральная и выборочная средняя
5. Показатели вариации. Генеральная и выборочная дисперсия
6. Формула дисперсии, стандартное отклонение, коэффициент вариации
7. Асимметрия и эксцесс эмпирического распределения
8. Статистические оценки параметров генеральной совокупности
9. Оценка вероятности биномиального распределения
10. Оценки по повторной и бесповторной выборке
12. Проверка статистических гипотез
13. Гипотеза о законе распределения генеральной совокупности
...Как ваша форма? Продолжаем!
14. Группировка данных. Виды группировок. Перегруппировка
15. Общая, групповые, внутригрупповая и межгрупповая дисперсия
17. Комбинационная группировка
19. Линейный коэффициент корреляции
20. Уравнение линейной регрессии
21. Проверка значимости линейной корреляционной модели
22. Модель однофакторной регрессии. Индекс детерминации
23. Нелинейная регрессия. Виды и примеры решений
24. Коэффициент ранговой корреляции Спирмена
25. Коэффициент корреляции Фехнера
26. Уравнение множественной линейной регрессии
До скорых встреч!
Решения и ответы:
Пример 3:
а) Используем простую среднюю:
![]() ц/га – в среднем по трём областям.
ц/га – в среднем по трём областям.
б) Используем средневзвешенную (по площади) среднюю:
![]()
![]() ц/га в среднем по трём областям.
ц/га в среднем по трём областям.
в) Здесь урожайность тоже следует переоценить через посевную площадь, используя формулу Посевная площадь = Валовой сбор / Урожайность:
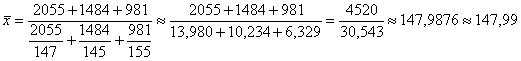 ц/га в среднем по трём областям. Такой вид средней иногда называют средней гармонической.
ц/га в среднем по трём областям. Такой вид средней иногда называют средней гармонической.
И здесь часто задают вопрос по размерности, комментирую: за размерностью можно проследить в бравом физико-математическом стиле. В числителе у нас расположены тысячи тонн (миллионы кг). В знаменателе миллионы кг делим на центнеры с га, избавляемся от трёхэтажности и сокращаем дробь на 100 кг:
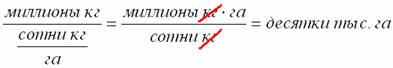 (общая посевная площадь)
(общая посевная площадь)
И, наконец, размерность всей дроби:
![]() или центнеры с га.
или центнеры с га.
Автор: Емелин Александр


Высшая математика для заочников и не только >>>
(Переход на главную страницу)
 © Copyright
© Copyright