

 Высшая математика – просто и доступно!
Высшая математика – просто и доступно!
 Если сайт упал, используйте ЗЕРКАЛО: mathprofi.net
Если сайт упал, используйте ЗЕРКАЛО: mathprofi.net
Наш форум, библиотека и блог: mathprofi.com
Математические формулы,
таблицы и другие материалы


Высшая математика для чайников, или с чего начать?
 Повторяем школьный курс
Повторяем школьный курс
Аналитическая геометрия:
Векторы для чайников
Скалярное произведение
векторов
Линейная (не) зависимость
векторов. Базис векторов
Переход к новому базису
Векторное и смешанное
произведение векторов
Формулы деления отрезка
в данном отношении
Прямая на плоскости
Простейшие задачи
с прямой на плоскости
Линейные неравенства
Как научиться решать задачи
по аналитической геометрии?
Линии второго порядка. Эллипс
Гипербола и парабола
Задачи с линиями 2-го порядка
Как привести уравнение л. 2 п.
к каноническому виду?
Полярные координаты
Как построить линию
в полярной системе координат?
Уравнение плоскости
Прямая в пространстве
Задачи с прямой в пространстве
Основные задачи
на прямую и плоскость
Треугольная пирамида
Элементы высшей алгебры:
Множества и действия над ними
Основы математической логики
Формулы и законы логики
Уравнения высшей математики
Как найти рациональные корни
многочлена? Схема Горнера
Комплексные числа
Выражения, уравнения и с-мы
с комплексными числами
Действия с матрицами
Как вычислить определитель?
Свойства определителя
и понижение его порядка
Как найти обратную матрицу?
Свойства матричных операций.
Матричные выражения
Матричные уравнения
Как решить систему линейных уравнений?
Правило Крамера. Матричный метод решения системы
Метод Гаусса для чайников
Несовместные системы
и системы с общим решением
Как найти ранг матрицы?
Однородные системы
линейных уравнений
Метод Гаусса-Жордана
Решение системы уравнений
в различных базисах
Линейные преобразования
Собственные значения
и собственные векторы
Квадратичные формы
Как привести квадратичную
форму к каноническому виду?
Ортогональное преобразование
квадратичной формы
Пределы:
Пределы. Примеры решений
Замечательные пределы
Методы решения пределов
Бесконечно малые функции.
Эквивалентности
Правила Лопиталя
Сложные пределы
Пределы последовательностей
Пределы по Коши. Теория
Производные функций:
Как найти производную?
Производная сложной функции. Примеры решений
Простейшие задачи
с производной
Логарифмическая производная
Производные неявной функции,
параметрически заданной
Производные высших порядков
Что такое производная?
Производная по определению
Как найти уравнение нормали?
Приближенные вычисления
с помощью дифференциала
Метод касательных
Функции и графики:
Графики и свойства
элементарных функций
Как построить график функции
с помощью преобразований?
Непрерывность, точки разрыва
Область определения функции
Асимптоты графика функции
Интервалы знакопостоянства
Возрастание, убывание
и экстремумы функции
Выпуклость, вогнутость
и точки перегиба графика
Полное исследование функции
и построение графика
Наибольшее и наименьшее
значения функции на отрезке
Экстремальные задачи
ФНП:
Область определения функции
двух переменных. Линии уровня
Основные поверхности
Предел функции 2 переменных
Повторные пределы
Непрерывность функции 2п
Частные производные
Частные производные
функции трёх переменных
Производные сложных функций
нескольких переменных
Как проверить, удовлетворяет
ли функция уравнению?
Частные производные
неявно заданной функции
Производная по направлению
и градиент функции
Касательная плоскость и
нормаль к поверхности в точке
Экстремумы функций
двух и трёх переменных
Условные экстремумы
Наибольшее и наименьшее
значения функции в области
Метод наименьших квадратов
Интегралы:
Неопределенный интеграл.
Примеры решений
Метод замены переменной
в неопределенном интеграле
Интегрирование по частям
Интегралы от тригонометрических функций
Интегрирование дробей
Интегралы от дробно-рациональных функций
Интегрирование иррациональных функций
Сложные интегралы
Определенный интеграл
Как вычислить площадь
с помощью определенного интеграла?
Что такое интеграл?
Теория для чайников
Объем тела вращения
Несобственные интегралы
Эффективные методы решения
определенных и несобственных
интегралов
Как исследовать сходимость
несобственного интеграла?
Признаки сходимости несобств.
интегралов второго рода
Абсолютная и условная
сходимость несобств. интеграла
S в полярных координатах
S и V, если линия задана
в параметрическом виде
Длина дуги кривой
S поверхности вращения
Приближенные вычисления
определенных интегралов

Метод прямоугольников
 Карта сайта
Карта сайта 
Дифференциальные уравнения:
Дифференциальные уравнения первого порядка
Однородные ДУ 1-го порядка
ДУ, сводящиеся к однородным
Линейные неоднородные дифференциальные уравнения первого порядка
Дифференциальные уравнения в полных дифференциалах
Уравнение Бернулли
Дифференциальные уравнения
с понижением порядка
Однородные ДУ 2-го порядка
Неоднородные ДУ 2-го порядка
Линейные дифференциальные
уравнения высших порядков
Метод вариации
произвольных постоянных
Как решить систему
дифференциальных уравнений
Задачи с диффурами
Методы Эйлера и Рунге-Кутты
Числовые ряды:
Ряды для чайников
Как найти сумму ряда?
Признак Даламбера.
Признаки Коши
Знакочередующиеся ряды. Признак Лейбница
Ряды повышенной сложности
Функциональные ряды:
Степенные ряды
Разложение функций
в степенные ряды
Сумма степенного ряда
Равномерная сходимость
Другие функциональные ряды
Приближенные вычисления
с помощью рядов
Вычисление интеграла разложением функции в ряд
Как найти частное решение ДУ
приближённо с помощью ряда?
Вычисление пределов
Ряды Фурье. Примеры решений
Кратные интегралы:
Двойные интегралы
Как вычислить двойной
интеграл? Примеры решений
Двойные интегралы
в полярных координатах
Как найти центр тяжести
плоской фигуры?
Тройные интегралы
Как вычислить произвольный
тройной интеграл?
Криволинейные интегралы
Интеграл по замкнутому контуру
Формула Грина. Работа силы
Поверхностные интегралы
Элементы векторного анализа:
Основы теории поля
Поток векторного поля
Дивергенция векторного поля
Формула Гаусса-Остроградского
Циркуляция векторного поля
и формула Стокса
Комплексный анализ:
ТФКП для начинающих
Как построить область
на комплексной плоскости?
Линии на С. Параметрически
заданные линии
Отображение линий и областей
с помощью функции w=f(z)
Предел функции комплексной
переменной. Примеры решений
Производная комплексной
функции. Примеры решений
Как найти функцию
комплексной переменной?
Конформное отображение
Решение ДУ методом
операционного исчисления
Как решить систему ДУ
операционным методом?
Теория вероятностей:
Основы теории вероятностей
Задачи по комбинаторике
Задачи на классическое
определение вероятности
Геометрическая вероятность
Задачи на теоремы сложения
и умножения вероятностей
Зависимые события
Формула полной вероятности
и формулы Байеса
Независимые испытания
и формула Бернулли
Локальная и интегральная
теоремы Лапласа
Статистическая вероятность
Случайные величины.
Математическое ожидание
Дисперсия дискретной
случайной величины
Функция распределения
Геометрическое распределение
Биномиальное распределение
Распределение Пуассона
Гипергеометрическое
распределение вероятностей
Непрерывная случайная
величина, функции F(x) и f(x)
Как вычислить математическое
ожидание и дисперсию НСВ?
Равномерное распределение
Показательное распределение
Нормальное распределение
Система случайных величин
Зависимые и независимые
случайные величины
Двумерная непрерывная
случайная величина
Зависимость и коэффициент
ковариации непрерывных СВ
Математическая статистика:
Математическая статистика
Дискретный вариационный ряд
Интервальный ряд
Мода, медиана, средняя
Показатели вариации
Формула дисперсии, среднее
квадратическое отклонение,
коэффициент вариации
Асимметрия и эксцесс
эмпирического распределения
Статистические оценки
и доверительные интервалы
Оценка вероятности
биномиального распределения
Оценки по повторной
и бесповторной выборке
Статистические гипотезы
Проверка гипотез. Примеры
Гипотеза о виде распределения
Критерий согласия Пирсона
Группировка данных. Виды группировок. Перегруппировка
Общая, внутригрупповая
и межгрупповая дисперсия
Аналитическая группировка
Комбинационная группировка
Эмпирические показатели
Как вычислить линейный
коэффициент корреляции?
Уравнение линейной регрессии
Проверка значимости линейной
корреляционной модели
Модель пАрной регрессии.
Индекс детерминации
Нелинейная регрессия. Виды и
примеры решений
Коэффициент ранговой
корреляции Спирмена
Коэф-т корреляции Фехнера
Уравнение множественной
линейной регрессии
Ряды динамики. Базисные,
цепные и средние показатели
Сглаживание временнОго ряда
Не нашлось нужной задачи?
Сборники готовых решений!
Не получается пример?
Задайте вопрос на форуме!
>>> mathprofi
Часто задаваемые вопросы
Гостевая книга
Отблагодарить автора >>>
Заметили опечатку / ошибку?
Пожалуйста, сообщите мне об этом
22. Модель однофакторной регрессии.
Индекс детерминации и индекс корреляции
По доброй традиции сразу разберёмся с терминами. Однофакторная регрессия и пАрная регрессия – это синонимы. С частным (линейным) случаем этой модели мы уже имели дело ранее. Так, в Примере 67 речь шла о корреляционной зависимости суммарной успеваемости (признак-результат) от количества прогулов (признак-фактор) за некоторый период времени. В рамках этой модели рассматривается один фактор, а посему её называют однофакторной. С другой стороны, признаков два, а значит, модель можно назвать и пАрной.
На предыдущих занятиях мы строили уравнения линейной регрессии, причём материал был рассмотрен в популярном стиле – для самого широкого круга читателей. И, возможно, вам вполне хватит уроков:
19. Линейный коэффициент корреляции
20. Уравнение линейной регрессии и
21. Проверка значимости линейной модели – да, даже это рассмотрели.
И сейчас 22-й урок, где я разберу математический смысл однофакторной регрессии, при этом изложенные ниже факты и методы решения работают как в линейном, так и в нелинейном случае! Схема универсальна. После чего мы, конечно, потренируемся в построении нелинейных моделей. Вы их долго-долго ждали и, наконец, дождались!
Конкретная задача и знакомая выборка, приступаем:
Пример 73
Имеются выборочные данные по ![]() студентам:
студентам: ![]() – количество прогулов за некоторый период времени и
– количество прогулов за некоторый период времени и ![]() – суммарная успеваемость за этот период:
– суммарная успеваемость за этот период:
![]()
Требуется:
1) высказать предположение о наличии и направлении корреляционной зависимости признака-результата ![]() от признака-фактора
от признака-фактора ![]() и построить диаграмму рассеяния;
и построить диаграмму рассеяния;
2) анализируя диаграмму рассеяния, сделать вывод о форме зависимости;
3) найти уравнение регрессии ![]() на
на ![]() ;
;
4) вычислить индекс детерминации и индекс корреляции;
5) проверить значимость выборочного уравнения регрессии на уровне значимости ![]() ;
;
6) найти среднюю ошибку аппроксимации.
По каждому пункту сделать выводы
Пункты 1-3 уже выполнены в Примере 67, и я конспективно приведу ключевые результаты. В ходе решения было высказано предположение о наличии обратной корреляционной зависимости успеваемости от количества прогулов, что подтвердилось диаграммой рассеяния:
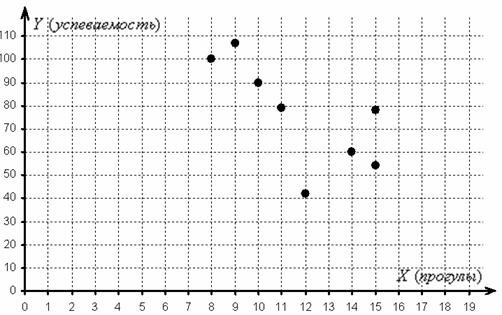
Эмпирические точки имеют тенденцию располагаться вдоль прямой, и поэтому корреляционная зависимость, вероятно, близкА к линейной. Далее методом наименьших квадратов мы нашли уравнение линейной регрессии, которое наилучшим образом приближает выборочные данные:
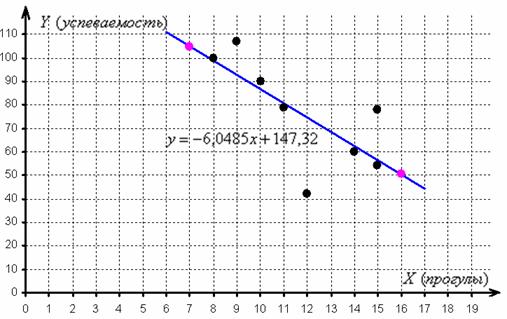
Вопрос: как оценить качество модели? Иными словами, насколько удачно линейная функция приближает эмпирические точки? На этот вопрос мы ответили с помощью линейного коэффициента корреляции и коэффициента детерминации. Однако это лишь частные показатели. Дело в том, что существует общий подход и универсальные показатели, которые годятся как в линейном, так и в нелинейном случае:
4) Найдём индекс детерминации и индекс корреляции.
Но прежде вникнем в математическую суть регрессионной модели. Предположим, что в нашем распоряжении есть данные только о суммарной успеваемости студентов за некоторый период времени:
![]() – Иванов;
– Иванов;
![]() – Петров;
– Петров;
![]() – Сидоров;
– Сидоров;
…
![]() – Попова.
– Попова.
Вычислим среднюю успеваемость по выборке:
![]() балла.
балла.
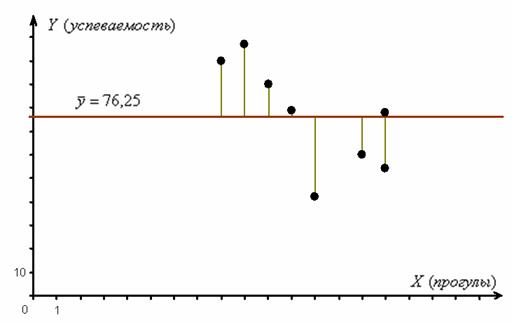
Совершенно понятно, что отдельно взятые значения успеваемости ![]() варьируются относительно среднего значения:
варьируются относительно среднего значения:
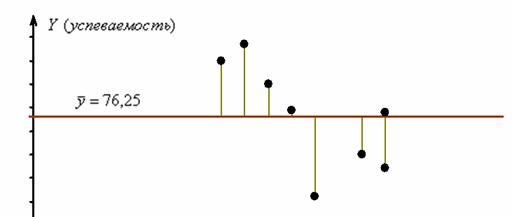
Я не нарисовал ось ![]() , так как пока мы рассматриваем единственный признак – успеваемость. Кстати, все точки можно было отложить прямо на оси
, так как пока мы рассматриваем единственный признак – успеваемость. Кстати, все точки можно было отложить прямо на оси ![]() , но для наглядности пусть будет так.
, но для наглядности пусть будет так.
Как оценить степень рассеяния значений ![]() относительно
относительно ![]() ? …Если вы затрудняетесь с ответом, то это, конечно, «двойка»! Меру разброса значений относительно средней характеризует дисперсия:
? …Если вы затрудняетесь с ответом, то это, конечно, «двойка»! Меру разброса значений относительно средней характеризует дисперсия:
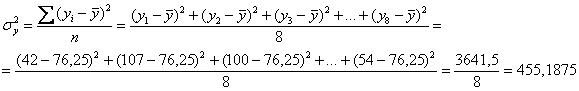
С геометрической точки зрения, сумма ![]() – это сумма квадратов хаки-отклонений на рисунке выше. …Все поняли эту фразу? Хаки – это цвет такой. И это не «каки» :) Кстати, а зачем возводить в квадрат? Это мы тоже разбирали, когда знакомились с понятием дисперсии: дело в том, что отклонения
– это сумма квадратов хаки-отклонений на рисунке выше. …Все поняли эту фразу? Хаки – это цвет такой. И это не «каки» :) Кстати, а зачем возводить в квадрат? Это мы тоже разбирали, когда знакомились с понятием дисперсии: дело в том, что отклонения ![]() могут быть как положительными, так и отрицательными, и просто так их просуммировать не получится (они взаимоуничтожатся). Чтобы преодолеть эту неприятность и подсчитать меру вариации – их и возводят в квадраты.
могут быть как положительными, так и отрицательными, и просто так их просуммировать не получится (они взаимоуничтожатся). Чтобы преодолеть эту неприятность и подсчитать меру вариации – их и возводят в квадраты.
Промежуточные вычисления удобно оформлять таблицей:
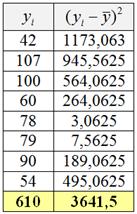
Сначала нашли сумму значений ![]() (левая нижняя ячейка), затем рассчитали
(левая нижняя ячейка), затем рассчитали ![]() , заполнили правый столбец и нашли дисперсию
, заполнили правый столбец и нашли дисперсию ![]() . Технически вычисления проще проводить в Экселе, и если вы до сих пор не знаете, как это делать, посмотрите, например, этот ролик.
. Технически вычисления проще проводить в Экселе, и если вы до сих пор не знаете, как это делать, посмотрите, например, этот ролик.
Теперь содержательный вопрос: а почему успеваемость вообще варьируется? На то есть множество причин, как неслучайных, так и случайных. У всех разные способности, кто-то учится прилежнее, кто-то прогуливает, кому-то повезло с темой / билетом, кому-то не повезло и так далее. Причин очень много, и дисперсия ![]() учитывает ВСЕ причины. А посему её называют общей дисперсией и иногда прямо так и обозначают:
учитывает ВСЕ причины. А посему её называют общей дисперсией и иногда прямо так и обозначают: ![]() . В качестве эквивалентной меры вариации часто рассматривают сумму
. В качестве эквивалентной меры вариации часто рассматривают сумму ![]() , которую называют общей суммой квадратов.
, которую называют общей суммой квадратов.
В нашей задаче предложен всего лишь один фактор, который влияет на успеваемость – количество прогулов:
Именно поэтому модель и называют однофакторной, прозанудствую ещё раз. Разумеется, можно рассмотреть и какой-нибудь другой фактор, влияющий на успеваемость, и даже несколько факторов, но вот у нас даны только прогулы.
Далее нами был визуально установлен линейный характер зависимости, и из решения системы 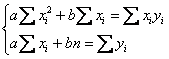 мы нашли уравнение линейной регрессии
мы нашли уравнение линейной регрессии ![]() (см. Пример 67, пункт 3).
(см. Пример 67, пункт 3).
В рамках построенной модели вся вариация успеваемости делится на две части:
– факторная (зелёный цвет на рис. ниже) – это та часть, которая объяснИма уравнением регрессии (фактором прогулов);
– и остаточная (красный цвет) – часть, которая регрессией не объясняется.
Так, при количестве прогулов ![]() отклонение
отклонение ![]() (хаки-отрезок слева вверху на рисунке ниже) обусловлено всеми причинами, повлиявшими на успеваемость. При этом точка
(хаки-отрезок слева вверху на рисунке ниже) обусловлено всеми причинами, повлиявшими на успеваемость. При этом точка ![]() делит данный отрезок на две части:
делит данный отрезок на две части:
– зелёный участок ![]() – это часть вариации, объяснённая уравнением регрессии;
– это часть вариации, объяснённая уравнением регрессии;
– красный участок ![]() – это остаточная часть вариации, которая уравнением НЕ объяснена. И в самом деле, если значение
– это остаточная часть вариации, которая уравнением НЕ объяснена. И в самом деле, если значение ![]() обусловлено количеством прогулов, то на добавочный остаток
обусловлено количеством прогулов, то на добавочный остаток ![]() приходятся другие факторы.
приходятся другие факторы.
Напоминаю, что метод наименьших квадратов состоит в том, чтобы подобрать ТАКУЮ прямую, чтобы сумма квадратов остатков ![]() была наименьшей. Грубо говоря, оптимальная (синяя) прямая должна проходить как можно ближе к эмпирическим точкам:
была наименьшей. Грубо говоря, оптимальная (синяя) прямая должна проходить как можно ближе к эмпирическим точкам:
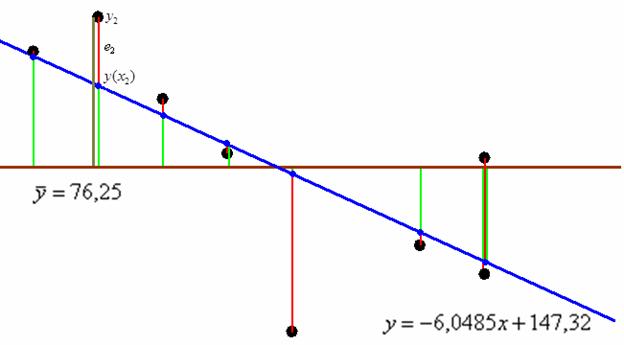
Таким образом, речь заходит о факторной сумме квадратов: ![]() (сумма квадратов зелёных отклонений) и об остаточной сумме квадратов
(сумма квадратов зелёных отклонений) и об остаточной сумме квадратов ![]() (сумма квадратов красных отклонений).
(сумма квадратов красных отклонений).
Соответственно, получаем факторную дисперсию ![]() и остаточную дисперсию
и остаточную дисперсию ![]() , при этом общая («игрековая») дисперсия успеваемости
, при этом общая («игрековая») дисперсия успеваемости ![]() – раскладывается на дисперсию, объяснённую уравнением регрессии, и дисперсию остаточную. По сути, это частный случай общей, межгрупповой и внутригрупповой дисперсии. Да, обращаю внимание, что дисперсии у нас выборочные (коль скоро они получены по выборке студентов) И аналогичное равенство, естественно, справедливо и для соответствующих сумм квадратов:
– раскладывается на дисперсию, объяснённую уравнением регрессии, и дисперсию остаточную. По сути, это частный случай общей, межгрупповой и внутригрупповой дисперсии. Да, обращаю внимание, что дисперсии у нас выборочные (коль скоро они получены по выборке студентов) И аналогичное равенство, естественно, справедливо и для соответствующих сумм квадратов: ![]() .
.
Очевидно, что чем длиннее зелёные отрезки, тем короче красные – тем больше значение ![]() и меньше
и меньше ![]() . Тем ближе эмпирические точки расположены к линии регрессии, и тем выше качество построенной модели. И мерилом такого качества является индекс детерминации:
. Тем ближе эмпирические точки расположены к линии регрессии, и тем выше качество построенной модели. И мерилом такого качества является индекс детерминации:
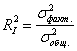 – это отношение выборочной факторной дисперсии к выборочной общей дисперсии. Следует заметить, что для расчёта этого индекса дисперсии находить не обязательно, достаточно ограничиться отношением сумм соответствующих квадратов:
– это отношение выборочной факторной дисперсии к выборочной общей дисперсии. Следует заметить, что для расчёта этого индекса дисперсии находить не обязательно, достаточно ограничиться отношением сумм соответствующих квадратов:
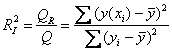 – именно такой вариант встречается в большинстве источников.
– именно такой вариант встречается в большинстве источников.
Индекс детерминации изменяется в пределах ![]() и показывает долю вариации признака-результата, которая обусловлена признаком-фактором. …Если не очень понятно, то скоро дойдём до конкретных вычислений и выводов.
и показывает долю вариации признака-результата, которая обусловлена признаком-фактором. …Если не очень понятно, то скоро дойдём до конкретных вычислений и выводов.
В предельном случае ![]() все эмпирические точки расположены на линии регрессии, и речь идёт о строгой функциональной зависимости, в этом случае признак-фактор модели полностью объясняет всю вариацию признака результата:
все эмпирические точки расположены на линии регрессии, и речь идёт о строгой функциональной зависимости, в этом случае признак-фактор модели полностью объясняет всю вариацию признака результата: ![]() . И противоположный случай
. И противоположный случай ![]() – здесь факторная дисперсия равна нулю и общая дисперсия полностью объяснИма неучтёнными в модели причинами:
– здесь факторная дисперсия равна нулю и общая дисперсия полностью объяснИма неучтёнными в модели причинами: ![]() . При этом линия регрессии параллельна оси
. При этом линия регрессии параллельна оси ![]() и отражает тот факт, что при изменении значений «икс» среднеожидаемое значение «игрек» остаётся постоянным. Иными словами, фактор, положенный в основу модели, не оказывает никакого влияния на результат.
и отражает тот факт, что при изменении значений «икс» среднеожидаемое значение «игрек» остаётся постоянным. Иными словами, фактор, положенный в основу модели, не оказывает никакого влияния на результат.
И ещё раз обращаю внимание, что я освещаю общий подход – в той или иной задаче линия регрессия может быть не только прямой, но и кривой линией.
Ну а теперь вернёмся к нашей задаче и конкретным вычислениям. Общая сумма квадратов ![]() и общая дисперсия
и общая дисперсия ![]() успеваемости уже рассчитана выше, и индекс детерминации можно найти двумя путями: непосредственно вычислить факторную сумму квадратов
успеваемости уже рассчитана выше, и индекс детерминации можно найти двумя путями: непосредственно вычислить факторную сумму квадратов ![]() и отношение
и отношение ![]() . Либо найти остаточную сумму квадратов
. Либо найти остаточную сумму квадратов ![]() , после чего из равенства
, после чего из равенства ![]() выразить
выразить ![]() и получить то же самое значение:
и получить то же самое значение: ![]() .
.
Второй вариант более популярен, но мы рассмотрим оба, заодно и проверочка будет.
Способ первый:
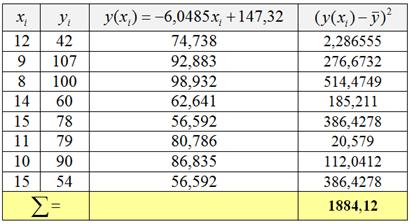
И на всякий случай расчёты для ![]() : сначала находим регрессионное значение
: сначала находим регрессионное значение ![]() , затем – соответствующий факторный квадрат:
, затем – соответствующий факторный квадрат:
![]() . Здесь и далее могут быть некоторые погрешности по причине округлений; со знаками «равно» и «примерно равно» я тоже не очень строг, поэтому не судите строго.
. Здесь и далее могут быть некоторые погрешности по причине округлений; со знаками «равно» и «примерно равно» я тоже не очень строг, поэтому не судите строго.
Факторная сумма квадратов найдена в таблице выше ![]() , осталось вычислить индекс детерминации:
, осталось вычислить индекс детерминации:
![]() – таким образом, в рамках построенной модели успеваемость на 51,74% зависит от количества прогулов. Оставшаяся часть вариации успеваемости (48,26%) обусловлена другими причинами.
– таким образом, в рамках построенной модели успеваемость на 51,74% зависит от количества прогулов. Оставшаяся часть вариации успеваемости (48,26%) обусловлена другими причинами.
Индекс детерминации совпал с линейным коэффициентом детерминации, который мы нашли в Примере 67, и я напомню, что сделанный вывод не является какой-то «абсолютной истиной», это всего лишь оценка в рамках построенной модели. А модель может быть подобрана как удачно, так и посредственно, а то и вовсе неудачно.
Табличка второго способа похожа:
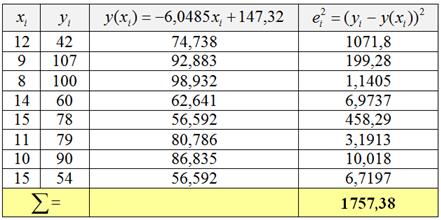
– за исключением последнего столбца, в котором рассчитываются квадраты остатков, так, для ![]() получаем:
получаем: ![]() .
.
Таким образом, остаточная сумма квадратов ![]() и индекс детерминации:
и индекс детерминации:
![]() – с тем же самым результатом и выводами.
– с тем же самым результатом и выводами.
Для качественной оценки тесноты связи используют индекс корреляции:
![]() – есть квадратный корень из индекса детерминации.
– есть квадратный корень из индекса детерминации.
Индекс корреляции тоже изменяется в пределах ![]() и для оценки качества модели используют уже знакомую многим шкалу Чеддока, вот один из её вариантов:
и для оценки качества модели используют уже знакомую многим шкалу Чеддока, вот один из её вариантов:
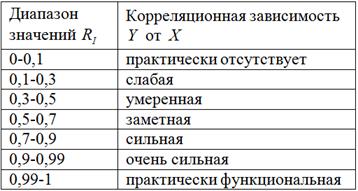
В нашей задаче:
![]() – таким образом, существует сильная корреляционная зависимость
– таким образом, существует сильная корреляционная зависимость ![]() – суммарной успеваемости от
– суммарной успеваемости от ![]() – количества прогулов.
– количества прогулов.
Результат совпал по модулю с линейным коэффициентом корреляции ![]() , который мы получили в ходе решения Примера 67. И, разумеется, вы поняли, что индекс корреляции не отражает направление зависимости (прямая или обратная). Но зато он годится для оценки качества как линейной, так и нелинейной регрессии! – рАвно, как и индекс детерминации, вычисленный по рассмотренной выше методике.
, который мы получили в ходе решения Примера 67. И, разумеется, вы поняли, что индекс корреляции не отражает направление зависимости (прямая или обратная). Но зато он годится для оценки качества как линейной, так и нелинейной регрессии! – рАвно, как и индекс детерминации, вычисленный по рассмотренной выше методике.
Индекс детерминации и индекс корреляции – это частный случай эмпирического коэффициента детерминации и эмпирического корреляционного отношения соответственно.
5) Оценим значимость построенной регрессионной модели, в данном случае линейной. Эту задачу мы уже решили на предыдущем уроке, но сейчас я разберу её в общем ключе.
Кратко напомню постановку вопроса: все вычисления выше и соответствующие результаты мы получили на основе выборочных данных, причём всего лишь по ![]() студентам. Но существует генеральная совокупность студентов, а значит, и генеральное уравнение регрессии
студентам. Но существует генеральная совокупность студентов, а значит, и генеральное уравнение регрессии ![]() с генеральным индексом детерминации
с генеральным индексом детерминации ![]() . И возникает вопрос: насколько можно доверять полученному выборочному уравнению
. И возникает вопрос: насколько можно доверять полученному выборочному уравнению ![]() и значению
и значению ![]() ? – они хорошо характеризуют генеральное уравнение
? – они хорошо характеризуют генеральное уравнение ![]() и индекс
и индекс ![]() ? Или не надёжно? – например, по причине малой выборки.
? Или не надёжно? – например, по причине малой выборки.
Проверка значимости выборочного уравнения регрессии эквивалентна проверке значимости выборочного индекса детерминации. …Кстати, почему? Ну хотя бы по той причине, что факторная сумма квадратов в числителе формулы ![]() порождена линией регрессии (вспоминаем недавний рисунок).
порождена линией регрессии (вспоминаем недавний рисунок).
Итак, на уровне значимости ![]() (согласно условию) проверим нулевую гипотезу:
(согласно условию) проверим нулевую гипотезу:
![]() – о том, что генеральный индекс детерминации равен нулю, то есть количество прогулов вообще никак (0%) не влияет на успеваемость.
– о том, что генеральный индекс детерминации равен нулю, то есть количество прогулов вообще никак (0%) не влияет на успеваемость.
– против конкурирующей гипотезы ![]() – о том, что такое влияние есть.
– о том, что такое влияние есть.
Для проверки гипотезы используем статистический критерий ![]() , где
, где ![]() – выборочная факторная сумма квадратов,
– выборочная факторная сумма квадратов, ![]() – выборочная остаточная сумма квадратов, а
– выборочная остаточная сумма квадратов, а ![]() – количество факторных (причинных) переменных
– количество факторных (причинных) переменных
В нашей модели фактор единственный (успеваемость) ![]() , следовательно, критерий принимает вид
, следовательно, критерий принимает вид ![]() . Эта случайная величина* имеет распределение Фишера (
. Эта случайная величина* имеет распределение Фишера (![]() -распределение) с количеством степеней свободы
-распределение) с количеством степеней свободы ![]() .
.
* Эта величина случайна, поскольку в разных исследованиях мы будем получать разные значения сумм квадратов, даже при том же объёме выборки.
Для уровня значимости ![]() и количества степеней свободы
и количества степеней свободы ![]() по соответствующей таблице или с помощью Расчётного макета (пункт 12) определяем критическое значение критерия:
по соответствующей таблице или с помощью Расчётного макета (пункт 12) определяем критическое значение критерия: ![]()
Теперь нужно вычислить наблюдаемое значение критерия. Если окажется что ![]() (красная область) то гипотезу
(красная область) то гипотезу ![]() на уровне значимости
на уровне значимости ![]() отвергаем. Если
отвергаем. Если ![]() , то отвергать её – оснований нет:
, то отвергать её – оснований нет:

В нашей задаче:
![]() – таким образом, на уровне значимости
– таким образом, на уровне значимости ![]() гипотезу
гипотезу ![]() отвергаем в пользу конкурирующей гипотезы
отвергаем в пользу конкурирующей гипотезы ![]() .
.
На практике факторную сумму квадратов часто не рассчитывают, обходясь остаточной и общей суммой: ![]() (из равенства
(из равенства ![]() ), а если найден индекс детерминации, то можно провести вычисления и через него:
), а если найден индекс детерминации, то можно провести вычисления и через него:
![]() – это наиболее распространённый вариант.
– это наиболее распространённый вариант.
Вывод: выборочный индекс детерминации ![]() статистически значимо отличается от нуля, следовательно, статистически значимо и выборочное уравнение
статистически значимо отличается от нуля, следовательно, статистически значимо и выборочное уравнение ![]() .
.
! Но: из этого ещё не следует, что построенная модель является качественной. Речь идёт лишь о её статистической значимости. …Не очень понятно? Для понимания можно привести такую фразу: успеваемость студента статистически значимо отличается от нуля. Но это может быть как студент-отличник, так и студент-удовлетворительник, так и почти уже не студент (но с какими-то шансами).
Вот и в нашей модели так – несмотря на её статистическую значимость, ещё не факт, что она сильно хорошА. И прояснить ситуацию нам поможет:
6) Средняя ошибка аппроксимации:
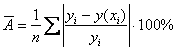 , которая показывает, на сколько процентов в среднем эмпирические значения
, которая показывает, на сколько процентов в среднем эмпирические значения ![]() отличаются от соответствующих значений
отличаются от соответствующих значений ![]() , вычисленных по уравнению регрессии.
, вычисленных по уравнению регрессии.
Разъясню подробнее. Так, количеству прогулов ![]() соответствует эмпирическая успеваемость в
соответствует эмпирическая успеваемость в ![]() баллов. А по полученному уравнению регрессии мы получили
баллов. А по полученному уравнению регрессии мы получили ![]() балла. И возникает интерес оценить разницу
балла. И возникает интерес оценить разницу ![]() , для этого её логично соотнести с эмпирическим значением:
, для этого её логично соотнести с эмпирическим значением: ![]() и тут сразу удобно выразить результат в процентах:
и тут сразу удобно выразить результат в процентах: ![]() . Таким образом, отклонение
. Таким образом, отклонение ![]() составляет 13,2% от эмпирического значения
составляет 13,2% от эмпирического значения ![]() , что, к слову, прилично (но ещё не до неприличия).
, что, к слову, прилично (но ещё не до неприличия).
И формула 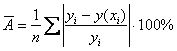 подсчитывает средний процент таких сопоставлений по всей совокупности. Знак модуля нужен по той причине, что отклонения
подсчитывает средний процент таких сопоставлений по всей совокупности. Знак модуля нужен по той причине, что отклонения ![]() , да и сами эмпирические значения
, да и сами эмпирические значения ![]() в общем случае могут быть отрицательными.
в общем случае могут быть отрицательными.
Совершенно понятно, что чем меньше средняя ошибка аппроксимации ![]() , тем лучше. Хорошим результатом считаются значения ниже 8-10%. В некоторых источниках встречается оценка в 15%, но это, конечно, многовато; в качестве компромисса будем считать такой результат удовлетворительным. Впрочем, это всё общие рассуждения – в некоторых задачах требуется повышенная точность, а в других она не критична.
, тем лучше. Хорошим результатом считаются значения ниже 8-10%. В некоторых источниках встречается оценка в 15%, но это, конечно, многовато; в качестве компромисса будем считать такой результат удовлетворительным. Впрочем, это всё общие рассуждения – в некоторых задачах требуется повышенная точность, а в других она не критична.
Проведём вычисления для нашей задачи, технически предыдущую таблицу удобно снабдить дополнительным столбцом:
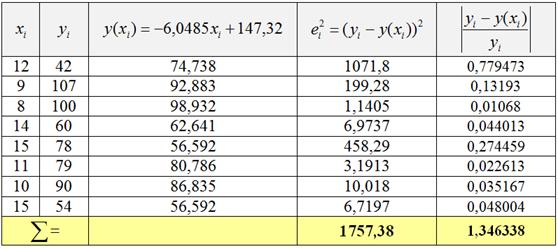
В результате 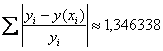 и средняя ошибка аппроксимации:
и средняя ошибка аппроксимации:
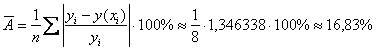 – таким образом, эмпирические
– таким образом, эмпирические ![]() и соответствующие регрессионные значения
и соответствующие регрессионные значения ![]() различаются в среднем на 16,83%.
различаются в среднем на 16,83%.
Вывод: качество модели удовлетворительно.
Готово.
И такие «скользкие» результаты – не случайность, дело в том, что регрессионная модель чувствительна к так называемым «выбросам» – единичным* точкам (* то есть, их мало), которые далекИ от регрессионной прямой.
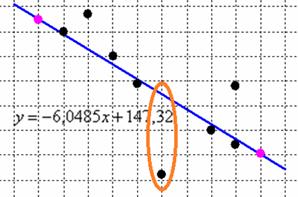
Подобные «выбросы» необоснованно увеличивают общую погрешность и искажают итоговые результаты. И поэтому аномальные значения стараются исключить из рассмотрения (а студента, очевидно, из института), достигая более или менее однородного состава совокупности. Кроме того, чтобы линейная модель была качественной, требуется выполнение условий Гаусса-Маркова, с которыми можно ознакомиться в многочисленных источниках, в частности тех, которые указаны ниже.
Я же ограничусь практической стороной вопроса и принципом «дана задача – нужно решать», невзирая на теоретические условия, предъявляемые к модели линейной пАрной регрессии. Желающим ознакомиться с этой моделью более подробно и более строго рекомендую следующую литературу:
Н. Ш. Кремер Б. А. Путко Эконометрика
И. И. Елисеева Эконометрика
и ещё мне понравилась нижегородская методичка ННГАСУ:
О. В. Любимцев О. Л. Любимцева Линейные регрессионные модели в эконометрике
Но, должен предупредить, что везде (или почти везде) разные обозначения, впрочем, это только закалит юного эконометриста :)
И пояснение по поводу «Эконометрики» – это название появилось исторически, по той причине, что регрессионные модели часто строили (и строят) в экономических исследованиях. Да, эконометрика считается самостоятельной дисциплиной, но с таким же успехом она могла бы называться какой-нибудь Соционометрикой. Ибо приложений, помимо экономических, просто тьма свет. Таким образом, то, что мы сейчас изучаем, логичнее считать частью математической статистики.
И мы продолжаем нарабатывать практику:
Пример 73
В результате выборочного исследования признака ![]() , зависящего от
, зависящего от ![]() , получено
, получено ![]() пар значений:
пар значений:
![]()
Требуется:
1) методом наименьших квадратов найти уравнение линейной регрессии ![]() на
на ![]() ;
;
2) вычислить индекс детерминации и индекс корреляции;
3) проверить значимость полученной модели на уровне значимости ![]() ;
;
4) вычислить среднюю ошибку аппроксимации;
5) построить диаграмму рассеяния и линию регрессии.
По каждому пункту сделать выводы.
Это пример для самостоятельного исследования, все числа уже в Экселе и вам осталось быстренько провести вычисления. Не ленимся! В образце, с которым можно свериться внизу страницы, я придерживался наиболее распространённой схемы решения, а именно, пункт 1 найден с помощью стандартного алгоритма, который освещён в статье Метод наименьших квадратов. В пункте 2 для нахождения индексов рассчитана остаточная сумма квадратов, как я уже отмечал, это наиболее ходовой способ.
И после этого важного примера можно перейти к изучению нелинейной регрессии.
Желаю успехов!
Решения и ответы:
Пример 73. Решение:
1) Методом наименьших квадратов найдём уравнение ![]() линейной регрессии
линейной регрессии ![]() на
на ![]() . Заполним расчётную таблицу:
. Заполним расчётную таблицу:
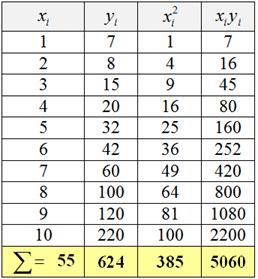
Коэффициенты уравнения ![]() найдём как решение системы:
найдём как решение системы:
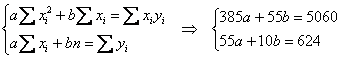
Систему решим по формулам Крамера:
![]() , значит, система имеет единственное решение.
, значит, система имеет единственное решение.

! Не забываем подставить полученные значения ![]() в каждое уравнение системы, выполнив тем самым проверку.
в каждое уравнение системы, выполнив тем самым проверку.
Таким образом, искомое уравнение регрессии:
![]()
Данное уравнение показывает, что с увеличением значения «икс» на 1 единицу соответствующее значение «игрек» увеличивается в среднем на 19,733 единицы. Очевидно, что корреляционная зависимость прямая («чем больше, тем больше»).
2) Найдём индекс детерминации и индекс корреляции. Вычислим среднее значение признака-результата ![]() и заполним расчётную таблицу:
и заполним расчётную таблицу:
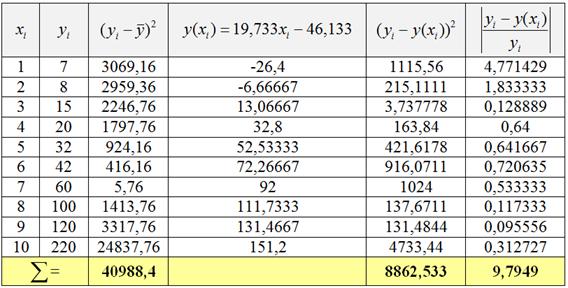
В результате, общая сумма квадратов ![]() , остаточная сумма квадратов
, остаточная сумма квадратов ![]() и индекс детерминации:
и индекс детерминации:
![]() – таким образом, в рамках построенной модели вариация признака
– таким образом, в рамках построенной модели вариация признака ![]() на 78,38% обусловлена изменением признака
на 78,38% обусловлена изменением признака ![]() . Остальные 21,62% вариации обусловлены причинами, не учтёнными в модели.
. Остальные 21,62% вариации обусловлены причинами, не учтёнными в модели.
Вычислим индекс корреляции:
![]() – таким образом, существует сильная корреляционная зависимость признака-результата
– таким образом, существует сильная корреляционная зависимость признака-результата ![]() от фактора
от фактора ![]() .
.
3) Оценим значимость построенной регрессионной модели на уровне значимости ![]() . А именно, проверим нулевую гипотезу
. А именно, проверим нулевую гипотезу ![]() – о том, что генеральный индекс детерминации равен нулю, против конкурирующей гипотезы:
– о том, что генеральный индекс детерминации равен нулю, против конкурирующей гипотезы: ![]() .
.
Используем статистический критерий 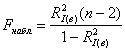 , где
, где ![]() – значение выборочного индекса детерминации.
– значение выборочного индекса детерминации.
Для уровня значимости ![]() и количества степеней свободы
и количества степеней свободы ![]() по соответствующей таблице или с помощью Расчётного макета (пункт 12) определяем критическое значение критерия:
по соответствующей таблице или с помощью Расчётного макета (пункт 12) определяем критическое значение критерия: ![]()
Вычислим наблюдаемое значение критерия:
![]()
Наблюдаемое значение критерия попало в критическую область ![]() :
:

– таким образом, на уровне значимости ![]() гипотезу
гипотезу ![]() отвергаем в пользу гипотезы
отвергаем в пользу гипотезы ![]() .
.
Вывод: индекс детерминации ![]() статистически значимо отличен от нуля, следовательно, статистически значимо и выборочное уравнение
статистически значимо отличен от нуля, следовательно, статистически значимо и выборочное уравнение ![]() .
.
4) Вычислим среднюю ошибку аппроксимации:
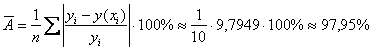 – таким образом, эмпирические
– таким образом, эмпирические ![]() и соответствующие регрессионные значения
и соответствующие регрессионные значения ![]() различаются в среднем почти в два раза, что, конечно, ни в какие ворота.
различаются в среднем почти в два раза, что, конечно, ни в какие ворота.
Вывод: качество модели неудовлетворительно.
5) Построим диаграмму рассеяния и линию регрессии по двум точкам ![]() :
:
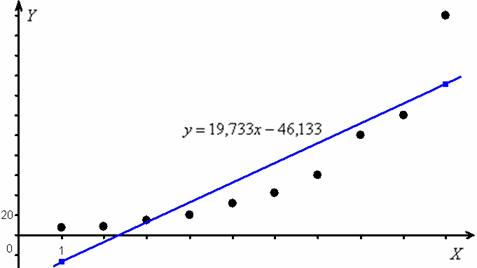
И, как мы видим, точки имеют тенденцию располагаться, скорее, вдоль некоторой кривой. Таким образом, здесь целесообразно использовать нелинейную регрессию, подобрав удачную аппроксимирующую кривую.
Автор: Емелин Александр


Высшая математика для заочников и не только >>>
(Переход на главную страницу)
 © Copyright
© Copyright