

 Высшая математика – просто и доступно!
Высшая математика – просто и доступно!
 Если сайт упал, используйте ЗЕРКАЛО: mathprofi.net
Если сайт упал, используйте ЗЕРКАЛО: mathprofi.net
Наш форум, библиотека и блог: mathprofi.com
Математические формулы,
таблицы и другие материалы


Высшая математика для чайников, или с чего начать?
 Повторяем школьный курс
Повторяем школьный курс
Аналитическая геометрия:
Векторы для чайников
Скалярное произведение
векторов
Линейная (не) зависимость
векторов. Базис векторов
Переход к новому базису
Векторное и смешанное
произведение векторов
Формулы деления отрезка
в данном отношении
Прямая на плоскости
Простейшие задачи
с прямой на плоскости
Линейные неравенства
Как научиться решать задачи
по аналитической геометрии?
Линии второго порядка. Эллипс
Гипербола и парабола
Задачи с линиями 2-го порядка
Как привести уравнение л. 2 п.
к каноническому виду?
Полярные координаты
Как построить линию
в полярной системе координат?
Уравнение плоскости
Прямая в пространстве
Задачи с прямой в пространстве
Основные задачи
на прямую и плоскость
Треугольная пирамида
Элементы высшей алгебры:
Множества и действия над ними
Основы математической логики
Формулы и законы логики
Уравнения высшей математики
Как найти рациональные корни
многочлена? Схема Горнера
Комплексные числа
Выражения, уравнения и с-мы
с комплексными числами
Действия с матрицами
Как вычислить определитель?
Свойства определителя
и понижение его порядка
Как найти обратную матрицу?
Свойства матричных операций.
Матричные выражения
Матричные уравнения
Как решить систему линейных уравнений?
Правило Крамера. Матричный метод решения системы
Метод Гаусса для чайников
Несовместные системы
и системы с общим решением
Как найти ранг матрицы?
Однородные системы
линейных уравнений
Метод Гаусса-Жордана
Решение системы уравнений
в различных базисах
Линейные преобразования
Собственные значения
и собственные векторы
Квадратичные формы
Как привести квадратичную
форму к каноническому виду?
Ортогональное преобразование
квадратичной формы
Пределы:
Пределы. Примеры решений
Замечательные пределы
Методы решения пределов
Бесконечно малые функции.
Эквивалентности
Правила Лопиталя
Сложные пределы
Пределы последовательностей
Пределы по Коши. Теория
Производные функций:
Как найти производную?
Производная сложной функции. Примеры решений
Простейшие задачи
с производной
Логарифмическая производная
Производные неявной функции,
параметрически заданной
Производные высших порядков
Что такое производная?
Производная по определению
Как найти уравнение нормали?
Приближенные вычисления
с помощью дифференциала
Метод касательных
Функции и графики:
Графики и свойства
элементарных функций
Как построить график функции
с помощью преобразований?
Непрерывность, точки разрыва
Область определения функции
Асимптоты графика функции
Интервалы знакопостоянства
Возрастание, убывание
и экстремумы функции
Выпуклость, вогнутость
и точки перегиба графика
Полное исследование функции
и построение графика
Наибольшее и наименьшее
значения функции на отрезке
Экстремальные задачи
ФНП:
Область определения функции
двух переменных. Линии уровня
Основные поверхности
Предел функции 2 переменных
Повторные пределы
Непрерывность функции 2п
Частные производные
Частные производные
функции трёх переменных
Производные сложных функций
нескольких переменных
Как проверить, удовлетворяет
ли функция уравнению?
Частные производные
неявно заданной функции
Производная по направлению
и градиент функции
Касательная плоскость и
нормаль к поверхности в точке
Экстремумы функций
двух и трёх переменных
Условные экстремумы
Наибольшее и наименьшее
значения функции в области
Метод наименьших квадратов
Интегралы:
Неопределенный интеграл.
Примеры решений
Метод замены переменной
в неопределенном интеграле
Интегрирование по частям
Интегралы от тригонометрических функций
Интегрирование дробей
Интегралы от дробно-рациональных функций
Интегрирование иррациональных функций
Сложные интегралы
Определенный интеграл
Как вычислить площадь
с помощью определенного интеграла?
Что такое интеграл?
Теория для чайников
Объем тела вращения
Несобственные интегралы
Эффективные методы решения
определенных и несобственных
интегралов
Как исследовать сходимость
несобственного интеграла?
Признаки сходимости несобств.
интегралов второго рода
Абсолютная и условная
сходимость несобств. интеграла
S в полярных координатах
S и V, если линия задана
в параметрическом виде
Длина дуги кривой
S поверхности вращения
Приближенные вычисления
определенных интегралов

Метод прямоугольников
 Карта сайта
Карта сайта 
Дифференциальные уравнения:
Дифференциальные уравнения первого порядка
Однородные ДУ 1-го порядка
ДУ, сводящиеся к однородным
Линейные неоднородные дифференциальные уравнения первого порядка
Дифференциальные уравнения в полных дифференциалах
Уравнение Бернулли
Дифференциальные уравнения
с понижением порядка
Однородные ДУ 2-го порядка
Неоднородные ДУ 2-го порядка
Линейные дифференциальные
уравнения высших порядков
Метод вариации
произвольных постоянных
Как решить систему
дифференциальных уравнений
Задачи с диффурами
Методы Эйлера и Рунге-Кутты
Числовые ряды:
Ряды для чайников
Как найти сумму ряда?
Признак Даламбера.
Признаки Коши
Знакочередующиеся ряды. Признак Лейбница
Ряды повышенной сложности
Функциональные ряды:
Степенные ряды
Разложение функций
в степенные ряды
Сумма степенного ряда
Равномерная сходимость
Другие функциональные ряды
Приближенные вычисления
с помощью рядов
Вычисление интеграла разложением функции в ряд
Как найти частное решение ДУ
приближённо с помощью ряда?
Вычисление пределов
Ряды Фурье. Примеры решений
Кратные интегралы:
Двойные интегралы
Как вычислить двойной
интеграл? Примеры решений
Двойные интегралы
в полярных координатах
Как найти центр тяжести
плоской фигуры?
Тройные интегралы
Как вычислить произвольный
тройной интеграл?
Криволинейные интегралы
Интеграл по замкнутому контуру
Формула Грина. Работа силы
Поверхностные интегралы
Элементы векторного анализа:
Основы теории поля
Поток векторного поля
Дивергенция векторного поля
Формула Гаусса-Остроградского
Циркуляция векторного поля
и формула Стокса
Комплексный анализ:
ТФКП для начинающих
Как построить область
на комплексной плоскости?
Линии на С. Параметрически
заданные линии
Отображение линий и областей
с помощью функции w=f(z)
Предел функции комплексной
переменной. Примеры решений
Производная комплексной
функции. Примеры решений
Как найти функцию
комплексной переменной?
Конформное отображение
Решение ДУ методом
операционного исчисления
Как решить систему ДУ
операционным методом?
Теория вероятностей:
Основы теории вероятностей
Задачи по комбинаторике
Задачи на классическое
определение вероятности
Геометрическая вероятность
Задачи на теоремы сложения
и умножения вероятностей
Зависимые события
Формула полной вероятности
и формулы Байеса
Независимые испытания
и формула Бернулли
Локальная и интегральная
теоремы Лапласа
Статистическая вероятность
Случайные величины.
Математическое ожидание
Дисперсия дискретной
случайной величины
Функция распределения
Геометрическое распределение
Биномиальное распределение
Распределение Пуассона
Гипергеометрическое
распределение вероятностей
Непрерывная случайная
величина, функции F(x) и f(x)
Как вычислить математическое
ожидание и дисперсию НСВ?
Равномерное распределение
Показательное распределение
Нормальное распределение
Система случайных величин
Зависимые и независимые
случайные величины
Двумерная непрерывная
случайная величина
Зависимость и коэффициент
ковариации непрерывных СВ
Математическая статистика:
Математическая статистика
Дискретный вариационный ряд
Интервальный ряд
Мода, медиана, средняя
Показатели вариации
Формула дисперсии, среднее
квадратическое отклонение,
коэффициент вариации
Асимметрия и эксцесс
эмпирического распределения
Статистические оценки
и доверительные интервалы
Оценка вероятности
биномиального распределения
Оценки по повторной
и бесповторной выборке
Статистические гипотезы
Проверка гипотез. Примеры
Гипотеза о виде распределения
Критерий согласия Пирсона
Группировка данных. Виды группировок. Перегруппировка
Общая, внутригрупповая
и межгрупповая дисперсия
Аналитическая группировка
Комбинационная группировка
Эмпирические показатели
Как вычислить линейный
коэффициент корреляции?
Уравнение линейной регрессии
Проверка значимости линейной
корреляционной модели
Модель пАрной регрессии.
Индекс детерминации
Нелинейная регрессия. Виды и
примеры решений
Коэффициент ранговой
корреляции Спирмена
Коэф-т корреляции Фехнера
Уравнение множественной
линейной регрессии
Ряды динамики. Базисные,
цепные и средние показатели
Сглаживание временнОго ряда
Не нашлось нужной задачи?
Сборники готовых решений!
Не получается пример?
Задайте вопрос на форуме!
>>> mathprofi
Часто задаваемые вопросы
Гостевая книга
Отблагодарить автора >>>
Заметили опечатку / ошибку?
Пожалуйста, сообщите мне об этом
21. Проверка значимости коэффициента корреляции, коэффициентов
и уравнения линейной регрессии. Доверительные интервалы
На предыдущих уроках мы научились рассчитывать линейный коэффициент корреляции ![]() и находить уравнение линейной регрессии
и находить уравнение линейной регрессии ![]() . Однако не всё так просто. Дело в том, что эти результаты получены на основе выборочных данных (почти всегда) и возникает вопрос: а насколько достоверно они отражают реальную картину?
. Однако не всё так просто. Дело в том, что эти результаты получены на основе выборочных данных (почти всегда) и возникает вопрос: а насколько достоверно они отражают реальную картину?
Ведь существует генеральная совокупность с генеральным линейным коэффициентом корреляции ![]() («ро») и генеральным уравнением
(«ро») и генеральным уравнением ![]() , и может статься, полученные по выборке значение
, и может статься, полученные по выборке значение ![]() и уравнение
и уравнение ![]() далеки от истины.
далеки от истины.
Ответить на этом вопрос нам помогут статистические гипотезы и доверительные интервалы. Сначала оглавление, затем примеры:
– Как проверить значимость выборочного линейного коэффициента корреляции?
– Как найти доверительный интервал для генерального коэффициента корреляции?
– Как проверить значимость коэффициентов уравнения линейной регрессии?
– Как найти доверительные интервалы для коэффициентов регрессии?
– Как проверить значимость выборочного уравнения линейной регрессии?
(значимость коэффициента детерминации)
 Да, и ещё видео есть (см. начало) по быстрому расчёту сего скарба в Экселе! Используйте для проверки подробного решения!
Да, и ещё видео есть (см. начало) по быстрому расчёту сего скарба в Экселе! Используйте для проверки подробного решения!
– Как найти доверительный интервал для точечного прогноза?
И сейчас мы быстренько разберёмся, что к чему. Опытные читатели могут сразу выбрать интересующий пункт, но я всё же рекомендую прочитать их по порядку, так как одно связано с другим:
Пример 71
По результатам Примера 67 найти всё перечисленное выше.
В той задаче нам была дана выборка из ![]() студентов:
студентов:
![]() ,
,
где ![]() – количество прогулов студента (за некоторый период времени) и
– количество прогулов студента (за некоторый период времени) и ![]() – его суммарная успеваемость за этот период
– его суммарная успеваемость за этот период
По ходу решения мы получили выборочный коэффициент ![]() , что говорит о сильной обратной корреляционной зависимости успеваемости
, что говорит о сильной обратной корреляционной зависимости успеваемости ![]() от количества прогулов
от количества прогулов ![]() . Кроме того, было найдено уравнение регрессии
. Кроме того, было найдено уравнение регрессии ![]() , которое показывает, что с увеличением количества прогулов на 1 единицу («икс») суммарная успеваемость падает в среднем на 6,0485 – примерно на 6 баллов.
, которое показывает, что с увеличением количества прогулов на 1 единицу («икс») суммарная успеваемость падает в среднем на 6,0485 – примерно на 6 баллов.
Но насколько можно доверять полученным результатам? Ведь перед нами выборка, причём, выборка малого объёма.
Решение, а точнее, небольшое исследование:
1) Проверим значимость выборочного коэффициента корреляции ![]() . Для этого рассмотрим нулевую гипотезу:
. Для этого рассмотрим нулевую гипотезу:
![]() – генеральный линейный коэффициент корреляции равен нулю, то есть успеваемость всех студентов не зависит от количества прогулов (линейно корреляционно).
– генеральный линейный коэффициент корреляции равен нулю, то есть успеваемость всех студентов не зависит от количества прогулов (линейно корреляционно).
Под словечком «всех» кроется изучаемая генеральная совокупность – можно рассмотреть студентов какого-то конкретного ВУЗа, либо студентов региона, либо студентов-приматов целой страны, либо вообще всех студентов на планете. Но здесь явно нет претензий на масштаб (выборка всего лишь 8 человек) – предположим, что исследуется успеваемость студентов вашего факультета.
В качестве альтернативной гипотезы стандартно рассматривают противоположное утверждение ![]() – о том, что линейная корреляционная зависимость успеваемости от количества прогулов существует. При этом направление зависимости (прямая или обратная) не принимается во внимание, поскольку категоричному утверждению о равенстве нулю логично противопоставить и положительные значения
– о том, что линейная корреляционная зависимость успеваемости от количества прогулов существует. При этом направление зависимости (прямая или обратная) не принимается во внимание, поскольку категоричному утверждению о равенстве нулю логично противопоставить и положительные значения ![]() . Ну а вдруг это факультет вундеркиндов, где прогулы только повышают успеваемость?
. Ну а вдруг это факультет вундеркиндов, где прогулы только повышают успеваемость?
Заметьте заодно, что это один из немногих случаев, когда нулевая гипотеза является менее правдоподобной, нежели альтернативная.
Алгоритм проверки гипотезы работает по стандартному трафарету, который мы неоднократно использовали ранее. Сначала нужно задать уровень значимости, коль скоро он не предложен в условии. Возьмём традиционное значение ![]() .
.
Для проверки гипотезы ![]() на уровне значимости
на уровне значимости ![]() используем статистический критерий
используем статистический критерий 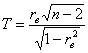 , где
, где ![]() – объём выборки, а
– объём выборки, а ![]() – выборочный коэффициент корреляции. Напоминаю, что статистический критерий – есть величина случайная. Почему? В данном случае потому, что в разных выборках мы будем получать разные значения
– выборочный коэффициент корреляции. Напоминаю, что статистический критерий – есть величина случайная. Почему? В данном случае потому, что в разных выборках мы будем получать разные значения ![]() . Эта случайная величина имеет распределение Стьюдента с количеством степеней свободы
. Эта случайная величина имеет распределение Стьюдента с количеством степеней свободы ![]() , где «эм» – количество оцениваемых параметров. Здесь пациент один (коэффициент корреляции):
, где «эм» – количество оцениваемых параметров. Здесь пациент один (коэффициент корреляции): ![]() , а посему
, а посему ![]() .
.
Чтобы проверить нулевую гипотезу, нужно найти критическое значение ![]() двусторонней критической области – для уровня значимости
двусторонней критической области – для уровня значимости ![]() и количества степеней свободы
и количества степеней свободы ![]() . В нашем случае
. В нашем случае ![]() и:
и:
![]() – это значение можно определить по таблице критических точек распределения Стьюдента (ориентируемся по верхней строке) либо с помощью соответствующей функции Экселя (пункт 10в).
– это значение можно определить по таблице критических точек распределения Стьюдента (ориентируемся по верхней строке) либо с помощью соответствующей функции Экселя (пункт 10в).
! Примечание: во многих источниках используют понятие квантиля распределения, который рассчитывается для вероятности ![]() , но чтобы не разводить путаницу я буду придерживаться прежней схемы решения.
, но чтобы не разводить путаницу я буду придерживаться прежней схемы решения.
Теперь нужно вычислить наблюдаемое значение критерия ![]() . Если оно попадёт в область принятия гипотезы
. Если оно попадёт в область принятия гипотезы ![]() (незаштрихованный участок на рисунке ниже), то на уровне значимости
(незаштрихованный участок на рисунке ниже), то на уровне значимости ![]() нет оснований отвергать гипотезу
нет оснований отвергать гипотезу ![]() . Если же
. Если же ![]() (
(![]() либо
либо ![]() – красный штрих), то нулевая гипотеза отвергается:
– красный штрих), то нулевая гипотеза отвергается:
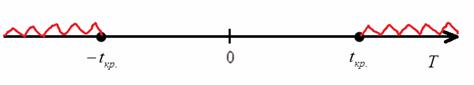
Проводим вычисления:
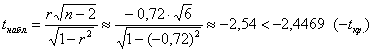 , таким образом, на уровне значимости
, таким образом, на уровне значимости ![]() гипотезу
гипотезу ![]() отвергаем в пользу гипотезы
отвергаем в пользу гипотезы ![]() .
.
Иными словами, выборочное значение ![]() оказалось статически значимым и вряд ли объяснимо случайными факторами (малой выборкой, например).
оказалось статически значимым и вряд ли объяснимо случайными факторами (малой выборкой, например).
При этом с вероятностью 0,05 мы совершили ошибку первого рода, то есть отвергли правильную гипотезу. Как видите, эта вероятность мала, а посему, уважаемые студенты, поменьше прогуливайте занятия, ибо статистическая проверка всего лишь по 8 студентам – и то – убедительно подтвердила падение успеваемости.
2) Теперь определим доверительный интервал для генерального линейного коэффициента корреляции ![]() .
.
Очевидно, что генеральный коэффициент ![]() может быть как меньше, так и больше выборочного результата
может быть как меньше, так и больше выборочного результата ![]() . И задача состоит в том, чтобы найти интервал
. И задача состоит в том, чтобы найти интервал ![]() , который с заранее заданной доверительной вероятностью (надёжностью)
, который с заранее заданной доверительной вероятностью (надёжностью) ![]() накроет истинное значение генерального коэффициента
накроет истинное значение генерального коэффициента ![]() :
:
![]()
Выберем популярное значение ![]() .
.
И тут развилка. Если выборка малА (ориентировочно ![]() ), то целесообразно использовать то же распределение Стьюдента с количеством степеней свободы
), то целесообразно использовать то же распределение Стьюдента с количеством степеней свободы ![]() . Это наш случай, и точность оценки в нём рассчитывается по формуле:
. Это наш случай, и точность оценки в нём рассчитывается по формуле:
![]()
Для уровня доверительной вероятности ![]() и количества степеней свободы
и количества степеней свободы ![]() находим коэффициент доверия:
находим коэффициент доверия: ![]() , например, с помощью Расчётного макета (пункт 10б).
, например, с помощью Расчётного макета (пункт 10б).
! Примечание: также можно использовать значение ![]() и пункт 10в макета.
и пункт 10в макета.
Таким образом:
![]()
и получается следующий интервал:
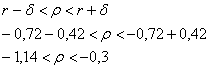
Поскольку коэффициент корреляции не может превосходить по модулю единицу, то левое значение корректируем:
![]() – итак, с вероятностью
– итак, с вероятностью ![]() данный интервал накрывает генеральный коэффициент корреляции
данный интервал накрывает генеральный коэффициент корреляции ![]() .
.
Да, оценка весьма грубА, но, так или иначе, задание выполнено. И, как вы правильно догадались, виновником такого результата является слишком малый объём выборки. Это хорошо видно и по формуле: ![]() – при увеличении
– при увеличении ![]() знаменатель растёт и, соответственно,
знаменатель растёт и, соответственно, ![]() уменьшается.
уменьшается.
Из формулы также нетрудно понять, что чем ближе выборочный коэффициент по модулю к единице, тем точнее будет оценка. Так, для ![]() и того же значения
и того же значения ![]() получается интервал
получается интервал ![]() , что уже очень и очень неплохо.
, что уже очень и очень неплохо.
Интервал можно сузить, уменьшив доверительную вероятность ![]() , однако это неприемлемо для серьезного статистического исследования. Поэтому остаётся лишь увеличивать объём выборки, и случай
, однако это неприемлемо для серьезного статистического исследования. Поэтому остаётся лишь увеличивать объём выборки, и случай ![]() я разберу в следующей задаче. Там всё занятнее, но зато точнее.
я разберу в следующей задаче. Там всё занятнее, но зато точнее.
3) Проверим значимость коэффициентов выборочного уравнения линейной регрессии ![]() . Иными словами, можно ли доверять значениям
. Иными словами, можно ли доверять значениям ![]() или они далеки от соответствующих коэффициентов генерального уравнения
или они далеки от соответствующих коэффициентов генерального уравнения ![]() ?
?
Наиболее важным является коэффициент «а» при факторной переменной, с него и начнём. По исходным данным ![]() (количество прогулов) и
(количество прогулов) и ![]() (соответствующая суммарная успеваемость) заполним следующую расчётную таблицу:
(соответствующая суммарная успеваемость) заполним следующую расчётную таблицу:
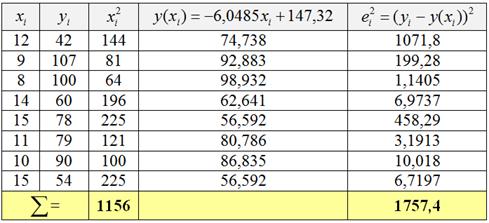
Примечание: если Пример 67 решён 1-м способом, то квадраты ![]() и их сумма
и их сумма ![]() уже найдены и в этом случае 3-й столбец не нужен. Он также не потребуется, если вам нужно проверить лишь коэффициент «а» (при факторной переменной «икс»).
уже найдены и в этом случае 3-й столбец не нужен. Он также не потребуется, если вам нужно проверить лишь коэффициент «а» (при факторной переменной «икс»).
В 4-м слева столбце с помощью выборочного уравнения регрессии рассчитываем среднеожидаемую успеваемость![]() студентов для эмпирических значений
студентов для эмпирических значений ![]() . Так, при количестве прогулов
. Так, при количестве прогулов ![]() среднеожидаемая успеваемость составит
среднеожидаемая успеваемость составит ![]() . И, наконец, в правом столбце находим квадраты отклонений
. И, наконец, в правом столбце находим квадраты отклонений ![]() эмпирических значений
эмпирических значений ![]() успеваемости от соответствующих среднеожидаемых значений
успеваемости от соответствующих среднеожидаемых значений ![]() , вычисленных по уравнению регрессии. Например:
, вычисленных по уравнению регрессии. Например: ![]() . О том, как быстро проводить подобные вычисления в Экселе, я неоднократно рассказывал ранее, посмотрИте хотя бы недавний ролик.
. О том, как быстро проводить подобные вычисления в Экселе, я неоднократно рассказывал ранее, посмотрИте хотя бы недавний ролик.
Теперь проверка, выберем тот же уровень значимости ![]() . Рассмотрим нулевую гипотезу
. Рассмотрим нулевую гипотезу ![]() – о том, что соответствующий коэффициент генерального уравнения
– о том, что соответствующий коэффициент генерального уравнения ![]() равен нулю. По сути это означает отсутствие линейной корреляционной зависимости между показателями.
равен нулю. По сути это означает отсутствие линейной корреляционной зависимости между показателями.
И здесь тоже используется категоричная альтернатива ![]() – гипотеза о том, что линейная корреляционная зависимость успеваемости от количества прогулов существует. Вновь обратите внимание, что направление гипотетической зависимости (прямая или обратная) не принимается во внимание, проверяется лишь тот факт – есть она или нет.
– гипотеза о том, что линейная корреляционная зависимость успеваемости от количества прогулов существует. Вновь обратите внимание, что направление гипотетической зависимости (прямая или обратная) не принимается во внимание, проверяется лишь тот факт – есть она или нет.
Для проверки гипотезы ![]() на уровне значимости
на уровне значимости ![]() используем статистический критерий
используем статистический критерий ![]() , где
, где ![]() – выборочное значение коэффициента, а
– выборочное значение коэффициента, а ![]() – стандартная ошибка коэффициента «а». Случайная величина
– стандартная ошибка коэффициента «а». Случайная величина ![]() имеет распределение Стьюдента с количеством степеней свободы
имеет распределение Стьюдента с количеством степеней свободы ![]() , где
, где ![]() – количество оцениваемых параметров. Параметр у нас один (коэффициент «а»), поэтому
– количество оцениваемых параметров. Параметр у нас один (коэффициент «а»), поэтому ![]() .
.
Для уровня значимости ![]() и количества степеней свободы
и количества степеней свободы ![]() по соответствующей таблице либо с помощью Экселя (пункт 10в) находим критическое значение двусторонней области
по соответствующей таблице либо с помощью Экселя (пункт 10в) находим критическое значение двусторонней области ![]() .
.
Если наблюдаемое значение критерия окажется в «красной» области (![]() либо
либо ![]() ), то нулевая гипотеза отвергается в пользу альтернативной; если же
), то нулевая гипотеза отвергается в пользу альтернативной; если же ![]() , то оснований отвергать её на данном уровне значимости – нет.
, то оснований отвергать её на данном уровне значимости – нет.
Наблюдаемое значение критерия найдём по формуле:
![]()
Выборочный коэффициент известен ![]() , а вот с его стандартной ошибкой придётся потрудиться:
, а вот с его стандартной ошибкой придётся потрудиться:
![]() , где
, где ![]() – среднее квадратическое отклонение признака-фактора (найдено в Примере 67), а «эс етое» – стандартная ошибка регрессии, которая отыскивается по формуле:
– среднее квадратическое отклонение признака-фактора (найдено в Примере 67), а «эс етое» – стандартная ошибка регрессии, которая отыскивается по формуле:
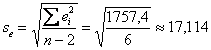 (сумма в числителе рассчитана в таблице выше).
(сумма в числителе рассчитана в таблице выше).
В результате:
![]() и наблюдаемое значение критерия:
и наблюдаемое значение критерия:
![]() , таким образом, на уровне значимости
, таким образом, на уровне значимости ![]() гипотезу
гипотезу ![]() отвергаем в пользу гипотезы
отвергаем в пользу гипотезы ![]() .
.
Иными словами, выборочное значение ![]() оказалось статически значимым и вряд ли объяснимо случайными факторами, малой выборкой, например.
оказалось статически значимым и вряд ли объяснимо случайными факторами, малой выборкой, например.
И внимательный читатель заметил, что здесь мы получили те же самые значения ![]() и
и ![]() , что и в первом пункте! То есть, проверка значимости коэффициента при факторной переменной («икс») эквивалентна проверке значимости коэффициента корреляции. Что неудивительно, ведь оба коэффициента характеризуют линейную корреляционную зависимость, да вспОмните хотя бы формулу
, что и в первом пункте! То есть, проверка значимости коэффициента при факторной переменной («икс») эквивалентна проверке значимости коэффициента корреляции. Что неудивительно, ведь оба коэффициента характеризуют линейную корреляционную зависимость, да вспОмните хотя бы формулу ![]() , в которой одно связано с другим.
, в которой одно связано с другим.
Таким образом, если проверен один коэффициент, то фактически проверен и другой. Впрочем, в вашей задаче может требоваться и то и другое. И третье, и четвёртое, и пятое :)
Следует добавить, что в некоторых задачах в качестве нулевой гипотезы выдвигают ![]() , где
, где ![]() – ненулевое значение. В этом случае наблюдаемое значение критерия рассчитывается по формуле
– ненулевое значение. В этом случае наблюдаемое значение критерия рассчитывается по формуле ![]() , а в остальном решение будет таким же.
, а в остальном решение будет таким же.
Но это ещё не всё. Проверим значимость коэффициента ![]() . Давайте, кстати, посмотрим на уравнение
. Давайте, кстати, посмотрим на уравнение ![]() и вспомним смысл этого коэффициента: если студент не прогулял ни одного занятия
и вспомним смысл этого коэффициента: если студент не прогулял ни одного занятия ![]() , то
, то ![]() – есть в точности среднеожидаемая успеваемость такого монстра :)
– есть в точности среднеожидаемая успеваемость такого монстра :)
В качестве нулевой гипотезы рассматриваем совсем уж невероятный случай ![]() о равенстве нулю коэффициента генерального уравнения
о равенстве нулю коэффициента генерального уравнения ![]() (этакий факультет эльфов, которые посещают все занятия, но никто вообще ничего не понимает :)).
(этакий факультет эльфов, которые посещают все занятия, но никто вообще ничего не понимает :)).
В качестве альтернативной гипотезы рассмотрим ![]() – о том, что не все из них эльфы.
– о том, что не все из них эльфы.
Решение будет «под кальку». Для проверки гипотезы ![]() на уровне значимости
на уровне значимости ![]() используем статистический критерий
используем статистический критерий ![]() , где
, где ![]() – выборочное значение коэффициента, а
– выборочное значение коэффициента, а ![]() – его стандартная ошибка. Эта случайная величина имеет то же распределение Стьюдента с количеством степеней свободы
– его стандартная ошибка. Эта случайная величина имеет то же распределение Стьюдента с количеством степеней свободы ![]() , и для уровня значимости
, и для уровня значимости ![]() мы определили
мы определили ![]() .
.
Знакомая картинка с областью отвержения (красный цвет) и областью принятия нулевой гипотезы:
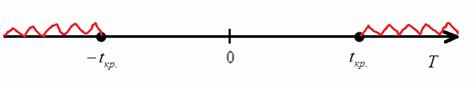
Вычислим стандартную ошибку коэффициента «бэ» (сумма квадратов найдена в таблице выше):
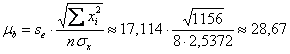 , как вариант, её можно рассчитать через стандартную ошибку коэффициента «а»:
, как вариант, её можно рассчитать через стандартную ошибку коэффициента «а»:
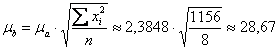 , что несколько проще.
, что несколько проще.
Вычислим наблюдаемое значение критерия:
![]() , таким образом, на уровне значимости
, таким образом, на уровне значимости ![]() гипотезу
гипотезу ![]() отвергаем в пользу гипотезы
отвергаем в пользу гипотезы ![]() .
.
То есть, выборочное значение ![]() статически значимо отличается от нуля, что естественно.
статически значимо отличается от нуля, что естественно.
В некоторых задачах рассматривают нулевую гипотезу ![]() , где
, где ![]() , и тогда наблюдаемое значение критерия рассчитывается по формуле
, и тогда наблюдаемое значение критерия рассчитывается по формуле ![]() .
.
4) Найдём доверительные интервалы для генеральных коэффициентов ![]() и
и ![]() . Это просто. Но оценка получится очень грубой, в частности потому, что выборка весьма малА.
. Это просто. Но оценка получится очень грубой, в частности потому, что выборка весьма малА.
Для первого коэффициента используем формулу:
![]()
Всё найдено в предыдущем пункте, осталось провести простецкие вычисления:
![]()
![]() – таким образом, с доверительной вероятностью
– таким образом, с доверительной вероятностью ![]() данный интервал накроет истинное значение генерального коэффициента
данный интервал накроет истинное значение генерального коэффициента ![]() .
.
И аналогичная формула для второго коэффициента:
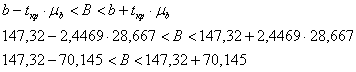
![]() – таким образом, с доверительной вероятностью
– таким образом, с доверительной вероятностью ![]() данный интервал накроет истинное значение генерального коэффициента
данный интервал накроет истинное значение генерального коэффициента ![]()
5) Проверим статистическую значимость всего выборочного уравнения ![]() – можно ли с высокой степенью доверять этому результату или он далёк от генерального уравнения
– можно ли с высокой степенью доверять этому результату или он далёк от генерального уравнения ![]() ? …Ну, после пунктов 1 и 3 доверять, очевидно, можно :) Но проблема состоит в том, что в разных задачах вам могут быть предложены разные пункты, и поэтому я разбираю каждый из них.
? …Ну, после пунктов 1 и 3 доверять, очевидно, можно :) Но проблема состоит в том, что в разных задачах вам могут быть предложены разные пункты, и поэтому я разбираю каждый из них.
На самом деле поставленный вопрос эквивалентен вопросу о проверке значимости выборочного коэффициента детерминации ![]() , который мы, естественно, тоже рассчитали в Примере 67. «Естественно», потому что
, который мы, естественно, тоже рассчитали в Примере 67. «Естественно», потому что ![]() – есть ключевой показатель. А именно, в рамках построенной линейной модели успеваемость на 51,74% зависит от количества прогулов. Оставшаяся часть вариации успеваемости (48,26%) обусловлена другими причинами, которые не учитываются уравнением
– есть ключевой показатель. А именно, в рамках построенной линейной модели успеваемость на 51,74% зависит от количества прогулов. Оставшаяся часть вариации успеваемости (48,26%) обусловлена другими причинами, которые не учитываются уравнением ![]() . В статье об индексе детерминации и корреляции я подробно обосную вышесказанное, ну а пока возвращаемся к делам нашим практическим.
. В статье об индексе детерминации и корреляции я подробно обосную вышесказанное, ну а пока возвращаемся к делам нашим практическим.
Поскольку ![]() , то проверка должна быть эквивалентна проверке значимости коэффициента корреляции (пункт 1). И это действительно так. Проверим гипотезу:
, то проверка должна быть эквивалентна проверке значимости коэффициента корреляции (пункт 1). И это действительно так. Проверим гипотезу:
![]() – о том, что генеральный коэффициент детерминации равен нулю, иными словами количество прогулов вообще никак (на 0%) не влияет на успеваемость.
– о том, что генеральный коэффициент детерминации равен нулю, иными словами количество прогулов вообще никак (на 0%) не влияет на успеваемость.
В качестве конкурирующей гипотезы рассмотрим логичное противопоставление ![]() – о том, что такое влияние есть.
– о том, что такое влияние есть.
Для проверки гипотезы используем статистический критерий ![]() , где
, где ![]() – значение выборочного коэффициента детерминации (которое от исследования к исследованию случайно), а
– значение выборочного коэффициента детерминации (которое от исследования к исследованию случайно), а ![]() – количество факторных (причинных) переменных. В нашей модели фактор один (успеваемость)
– количество факторных (причинных) переменных. В нашей модели фактор один (успеваемость) ![]() , а посему критерий принимает вид
, а посему критерий принимает вид ![]() . Эта случайная величина имеет распределение Фишера (
. Эта случайная величина имеет распределение Фишера (![]() -распределение) с количеством степеней свободы
-распределение) с количеством степеней свободы ![]() .
.
Для того же уровня значимости ![]() и количества степеней свободы
и количества степеней свободы ![]() по соответствующей таблице или с помощью расчётного макета (пункт 12) определяем критическое значение критерия:
по соответствующей таблице или с помощью расчётного макета (пункт 12) определяем критическое значение критерия: ![]()
Теперь вычислим наблюдаемое значение критерия. Если окажется что ![]() (красный штрих) то гипотезу
(красный штрих) то гипотезу ![]() на уровне значимости
на уровне значимости ![]() отвергаем; если же
отвергаем; если же ![]() , то отвергать её – оснований нет:
, то отвергать её – оснований нет:

В нашей задаче:
![]() , таким образом, на уровне значимости
, таким образом, на уровне значимости ![]() гипотезу
гипотезу ![]() отвергаем в пользу конкурирующей гипотезы
отвергаем в пользу конкурирующей гипотезы ![]() .
.
Иными словами, выборочное значение ![]() статистически значимо отлично от нуля, а значит, статистически значимо и выборочное уравнение
статистически значимо отлично от нуля, а значит, статистически значимо и выборочное уравнение ![]() . Однако «статистически значимо» – это ещё не значит, что «отлично» или хотя бы «хорошо». Так, и оценки «троечника» ведь статистически значимо отличны от нуля :)
. Однако «статистически значимо» – это ещё не значит, что «отлично» или хотя бы «хорошо». Так, и оценки «троечника» ведь статистически значимо отличны от нуля :)
Вполне может статься, что зависимость близкА и к какой-нибудь нелинейной – если эмпирические точки располагаются примерно по параболе, гиперболе, экспоненте или вдоль какой-нибудь другой кривой. В этом случае мы получим низкое значение линейного коэффициента детерминации и его статическую незначимость, а значит, и незначимость всей линейной модели. То есть, линейная модель будет неудовлетворительно описывать ситуацию. Подбор оптимальной кривой и нелинейные модели…– уже на ваших экранах!
Возвращаясь к взаимосвязи коэффициентов ![]() легко убедиться в том, что
легко убедиться в том, что ![]() – есть в точности критическое значение двусторонней области пункта 1, а
– есть в точности критическое значение двусторонней области пункта 1, а ![]() – есть в точности наблюдаемое значение того пункта.
– есть в точности наблюдаемое значение того пункта.
Таким образом, для линейной однофакторной модели эквивалентными являются следующие проверки:
– проверка значимости коэффициента корреляции;
– проверка значимости коэффициента факторной переменной уравнения регрессии;
– проверка значимость коэффициента детерминации.
И если проверено что-то одно, то по существу, проверено и второе и третье. Но, повторюсь, в вашей задаче вас могут заставить «пропахать» все три пункта.
И в заключение параграфа хочу добавить, что рассмотренный критерий Фишера работает и в многофакторных линейных моделях. ...Я, наконец, добрался до двухфакторной модели :) …на 13-й год развития сайта.
И на десерт:
6) Точечный прогноз и доверительный интервал прогноза.
Для чего нужно полученное уравнение ![]() ? Ну, конечно же, хочется что-нибудь спрогнозировать. Оценим суммарную успеваемость
? Ну, конечно же, хочется что-нибудь спрогнозировать. Оценим суммарную успеваемость ![]() при
при ![]() прогулах:
прогулах:
![]() баллов.
баллов.
Но это лишь точечный прогноз, вычисленный к тому же по выборочному уравнению. А ведь существует генеральное уравнение регрессии ![]() и, следовательно, генеральное прогнозируемое значение успеваемости
и, следовательно, генеральное прогнозируемое значение успеваемости ![]() при
при ![]() . И наша задача состоит в том, чтобы найти доверительный интервал:
. И наша задача состоит в том, чтобы найти доверительный интервал:
![]() – который с заранее заданной доверительной вероятностью
– который с заранее заданной доверительной вероятностью ![]() (например) накроет истинное значение
(например) накроет истинное значение ![]() .
.
Используем формулу ![]() , где
, где ![]() – коэффициент доверия, а
– коэффициент доверия, а ![]() – стандартная ошибка точечного прогноза.
– стандартная ошибка точечного прогноза.
Для уровня доверительной вероятности ![]() и количества степеней свободы
и количества степеней свободы ![]() находим коэффициент доверия
находим коэффициент доверия ![]() (Макет, пункт 10б).
(Макет, пункт 10б).
Стандартную ошибку точечного прогноза вычислим по формуле:
 , где
, где ![]() – стандартная ошибка регрессии (вычислена в пункте 3),
– стандартная ошибка регрессии (вычислена в пункте 3), ![]() – выборочное среднее значение признака-фактора (вычислено в ходе решения Примера 67),
– выборочное среднее значение признака-фактора (вычислено в ходе решения Примера 67), ![]() (вычислена там же, 2-й способ решения).
(вычислена там же, 2-й способ решения).
АККУРАТНО подставляем все значения и ВНИМАТЕЛЬНО считаем:
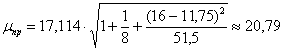
Таким образом, ![]() и искомый доверительный интервал:
и искомый доверительный интервал:
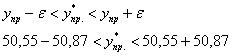
левое значение естественно округлим до нуля:
![]() – данный интервал с вероятностью
– данный интервал с вероятностью ![]() накрывает истинное генеральное значение
накрывает истинное генеральное значение ![]() прогноза успеваемости при
прогноза успеваемости при ![]() прогулах.
прогулах.
И оценка, конечно, опять получилась грубой, надежда, короче, для прогульщиков :) Но статистика, она неумолима – повезло раз, повезло два и может даже три, а потом….
Иными словами, при увеличении объема выборки наступает неизбежная закономерность.
И я рад, что вы читаете эти строки! Это нужно отметить. Аналогичной задачей, в которой исходные данные сведены в комбинационную таблицу:
Пример 72
По результатам Примера 69 на уровне значимости ![]() :
:
– проверить значимость выборочного линейного коэффициента корреляции;
– найти доверительный интервал для генерального коэффициента корреляции;
– проверить значимость коэффициентов уравнения линейной регрессии;
– найти доверительные интервалы для коэффициентов регрессии;
– проверить значимость выборочного уравнения линейной регрессии;
– найти доверительный интервал для прогнозного значения признака-результата, который соответствует ![]() .
.
В подобных ситуациях я традиционно предлагаю решить задачу самостоятельно, но здесь будет много новых моментов, а посему решаю сам. Итак, в Примере 69 по 40 предприятиям региона:
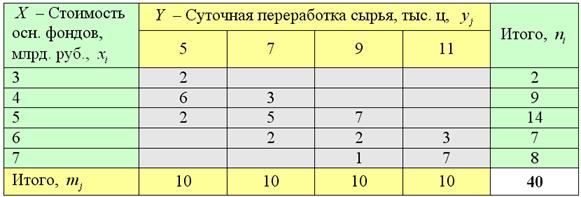
нами была установлена ![]() – сильная прямая линейная корреляционная зависимость суточной переработки сырья от стоимости основных фондов, а также найдено выборочное уравнение регрессии
– сильная прямая линейная корреляционная зависимость суточной переработки сырья от стоимости основных фондов, а также найдено выборочное уравнение регрессии ![]() , которое показывает, что при увеличении стоимости основных фондов на 1 млрд. руб. суточная переработка сырья увеличивается в среднем на 1,61 тысяч центнеров.
, которое показывает, что при увеличении стоимости основных фондов на 1 млрд. руб. суточная переработка сырья увеличивается в среднем на 1,61 тысяч центнеров.
…Все вникли в условие? Ещё раз перечитайте входные данные… Отлично! – поехали:
1) Проверим значимость выборочного коэффициента корреляции ![]() , а именно, рассмотрим гипотезу
, а именно, рассмотрим гипотезу ![]() против конкурирующей гипотезы
против конкурирующей гипотезы ![]() . Нулевая гипотеза говорит нам о том, что генеральный коэффициент корреляции (который, в принципе, можно рассчитать по ВСЕМ предприятиям региона), равен нулю, то есть линейная корреляционная зависимость отсутствует. И альтернатива утверждает, что эта зависимость (переработки сырья от стоимости фондов) существует.
. Нулевая гипотеза говорит нам о том, что генеральный коэффициент корреляции (который, в принципе, можно рассчитать по ВСЕМ предприятиям региона), равен нулю, то есть линейная корреляционная зависимость отсутствует. И альтернатива утверждает, что эта зависимость (переработки сырья от стоимости фондов) существует.
Для проверки гипотезы ![]() на уровне значимости
на уровне значимости ![]() используем статистический критерий
используем статистический критерий 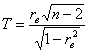 , где
, где ![]() – объём выборки, а
– объём выборки, а ![]() – выборочный коэффициент корреляции
– выборочный коэффициент корреляции
Для уровня значимости ![]() и количества степеней свободы
и количества степеней свободы ![]() с помощью соответствующей функции Экселя (пункт 10в) определяем критическое значение двусторонней области:
с помощью соответствующей функции Экселя (пункт 10в) определяем критическое значение двусторонней области: ![]()
Если окажется, что наблюдаемое значение критерия попадает в интервал ![]() , то оснований отвергать нулевую гипотезу – нет:
, то оснований отвергать нулевую гипотезу – нет:
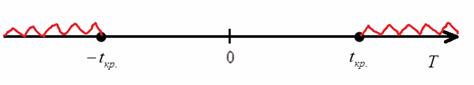
Проводим вычисления:
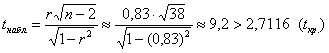 , таким образом, на уровне значимости
, таким образом, на уровне значимости ![]() гипотезу
гипотезу ![]() отвергаем в пользу гипотезы
отвергаем в пользу гипотезы ![]() .
.
Иными словами, выборочное значение ![]() статически значимо и вряд ли объяснимо случайными факторами, при этом с вероятностью 0,01 мы совершили ошибку первого рода, то есть отвергли правильную гипотезу (когда линейной зависимости на самом деле нет, но мы это отвергли).
статически значимо и вряд ли объяснимо случайными факторами, при этом с вероятностью 0,01 мы совершили ошибку первого рода, то есть отвергли правильную гипотезу (когда линейной зависимости на самом деле нет, но мы это отвергли).
2) Определим доверительный интервал для генерального линейного коэффициента корреляции ![]() . Поскольку выборка достаточно велика
. Поскольку выборка достаточно велика ![]() , то целесообразно использовать так называемое преобразование Фишера. Не вдаваясь в его содержательную суть, приведу формальный технический алгоритм.
, то целесообразно использовать так называемое преобразование Фишера. Не вдаваясь в его содержательную суть, приведу формальный технический алгоритм.
Преобразуем выборочный коэффициент корреляции по формуле:
![]() , это значение можно подсчитать на калькуляторе либо с помощью специальной функции Экселя (да, разработчики позаботились): =ФИШЕР(r).
, это значение можно подсчитать на калькуляторе либо с помощью специальной функции Экселя (да, разработчики позаботились): =ФИШЕР(r).
Вычислим стандартную ошибку коэффициента «зет»:
![]()
Для уровня доверительной вероятности ![]() из соотношения
из соотношения ![]() найдем коэффициент доверия
найдем коэффициент доверия ![]() :
:
![]() – определяем с помощью таблицы значений функции Лапласа либо по Макету (пункт 5*).
– определяем с помощью таблицы значений функции Лапласа либо по Макету (пункт 5*).
Вычислим нижнюю границу доверительного интервала:
![]()
и его верхнюю границу:
![]()
Теперь нужно вернуться в размерность нашей задачи с помощью обратного преобразования Фишера:
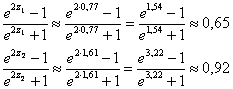
В Экселе эти значения легко рассчитать с помощью функции =ФИШЕРОБР( ) – для нижнего конца ![]() и для верхнего конца
и для верхнего конца ![]() .
.
Таким образом, искомый доверительный интервал:
![]() – с вероятностью
– с вероятностью ![]() накрывает генеральный коэффициент корреляции
накрывает генеральный коэффициент корреляции ![]() .
.
Следует заметить, что интервал получился довольно широким – по той причине, что мы задали суровую надёжность. Если её уменьшить, например, до ![]() , то получится более симпатичный результат:
, то получится более симпатичный результат: ![]() .
.
Рассмотренный метод хорошо работает, если выборка достаточно великА (20-30 наблюдений, по крайне мере) и коэффициент корреляции близок по модулю к единице.
3) Проверим статистическую значимость коэффициентов выборочного уравнения ![]() . Проверка будет трафаретной, но с некоторыми техническими новинками и хитростями.
. Проверка будет трафаретной, но с некоторыми техническими новинками и хитростями.
Сначала коэффициент при факторной («иксовой» переменной) ![]() . Выдвигаем нулевую гипотезу
. Выдвигаем нулевую гипотезу ![]() о том, что соответствующий коэффициент генерального уравнения
о том, что соответствующий коэффициент генерального уравнения ![]() равен нулю (т.е. линейной корреляционной зависимости не существует). В качестве конкурирующей гипотезы рассматриваем противоположное утверждение
равен нулю (т.е. линейной корреляционной зависимости не существует). В качестве конкурирующей гипотезы рассматриваем противоположное утверждение ![]() .
.
Чтобы проверить гипотезу ![]() на уровне значимости
на уровне значимости ![]() используем тот же критерий
используем тот же критерий ![]() , где
, где ![]() – выборочное значение коэффициента, а
– выборочное значение коэффициента, а ![]() – его стандартная ошибка.
– его стандартная ошибка.
Для уровня значимости ![]() и количества степеней свободы
и количества степеней свободы ![]() с помощью соответствующей функции Экселя (пункт 10в) находим критическое значение двусторонней области
с помощью соответствующей функции Экселя (пункт 10в) находим критическое значение двусторонней области ![]() .
.
Не поленюсь, для наглядности снова скопирую рисунок с областью отвержения (красный цвет) и областью принятия нулевой гипотезы:
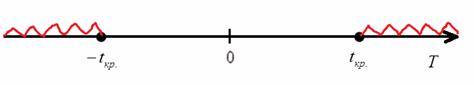
Наблюдаемое значение критерия найдём по формуле ![]() . И здесь вместо того, чтобы выполнять кропотливые вычисления по аналогии с предыдущей задачей, выгоднее использовать тот факт, что проверка значимости коэффициента корреляции равносильна проверке коэффициента при факторной переменной.
. И здесь вместо того, чтобы выполнять кропотливые вычисления по аналогии с предыдущей задачей, выгоднее использовать тот факт, что проверка значимости коэффициента корреляции равносильна проверке коэффициента при факторной переменной.
Вычислим стандартную ошибку коэффициента «а»:
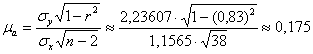
и наблюдаемое значение:
![]() , поэтому на уровне значимости
, поэтому на уровне значимости ![]() гипотезу
гипотезу ![]() отвергаем в пользу гипотезы
отвергаем в пользу гипотезы ![]() .
.
Примечание: поскольку ![]() , то фактически мы провели те же вычисления, что и в первом пункте.
, то фактически мы провели те же вычисления, что и в первом пункте.
Вывод: коэффициент ![]() статистически значим.
статистически значим.
Для проверки значимости коэффициента ![]() выдвигаем гипотезу
выдвигаем гипотезу ![]() о равенстве нулю соответствующего коэффициента генерального уравнения
о равенстве нулю соответствующего коэффициента генерального уравнения ![]() . Конкурирующая гипотеза стандартна:
. Конкурирующая гипотеза стандартна: ![]()
Критерий аналогичен: ![]() , где
, где ![]() – выборочное значение коэффициента, а
– выборочное значение коэффициента, а ![]() – стандартная ошибка этого коэффициента.
– стандартная ошибка этого коэффициента.
Уровню значимости ![]() и количеству степеней свободы
и количеству степеней свободы ![]() соответствует то же значение
соответствует то же значение ![]() и те же области:
и те же области:
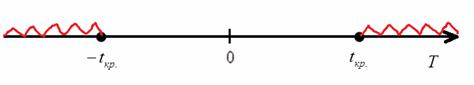
Стандартную ошибку коэффициента «бэ» рассчитаем через стандартную ошибку коэффициента «а»:
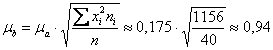 (сумма
(сумма ![]() найдена в Примере 69)
найдена в Примере 69)
Вычислим наблюдаемое значение критерия:
![]() – данное значение попало в область принятия гипотезы
– данное значение попало в область принятия гипотезы ![]() , поэтому на уровне значимости
, поэтому на уровне значимости ![]() нет оснований отвергать гипотезу
нет оснований отвергать гипотезу ![]() .
.
Вывод: коэффициент ![]() статистически не значим и его отличное от нуля значение, вероятнее всего, обусловлено статистической погрешностью выборки.
статистически не значим и его отличное от нуля значение, вероятнее всего, обусловлено статистической погрешностью выборки.
Таким образом, генеральное уравнение регрессии с высокой вероятностью имеет вид ![]() и самый что ни на есть реалистичный смысл: если стоимость фондов равна нулю
и самый что ни на есть реалистичный смысл: если стоимость фондов равна нулю ![]() , то суточная переработка сырья тоже нулевая.…Хотя, может статься, при нулевой балансовой стоимости сырьё начинают потихоньку разворовывать, и отрицательное значение
, то суточная переработка сырья тоже нулевая.…Хотя, может статься, при нулевой балансовой стоимости сырьё начинают потихоньку разворовывать, и отрицательное значение ![]() вовсе не случайно :) Кроме шуток, следует заметить, что на каких-то предприятиях это может и так, но статистическая проверка показала, что данный факт не характерен для всей генеральной совокупности.
вовсе не случайно :) Кроме шуток, следует заметить, что на каких-то предприятиях это может и так, но статистическая проверка показала, что данный факт не характерен для всей генеральной совокупности.
4) Найдём доверительные интервалы для генеральных коэффициентов ![]() и
и ![]() .
.
Для коэффициента при факторной переменной:
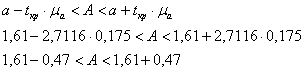
![]() – данный интервал с доверительной вероятностью
– данный интервал с доверительной вероятностью ![]() накрывает истинное значение генерального коэффициента
накрывает истинное значение генерального коэффициента ![]() .
.
Обратите внимание, что интервальная оценка получилась гораздо более качественной, нежели в предыдущем примере – вот что значит бОльший объём выборки. Но интервал, конечно, всё равно широк.
И доверительный интервал для свободного члена:
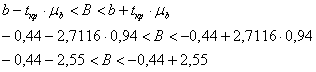
![]() – данный интервал с вероятностью
– данный интервал с вероятностью ![]() накрывает истинное значение генерального коэффициента
накрывает истинное значение генерального коэффициента ![]()
Да, оценка тривиальна, но примечательно, что ноль вошёл в эту область, и интервал получился почти симметричным относительно нуля.
5) Проверим статистическую значимость всего выборочного уравнения ![]() , а значит, выборочного коэффициента детерминации
, а значит, выборочного коэффициента детерминации ![]() .
.
Напоминаю, что эта проверка эквивалентна проверкам пунктов 1 и 3, и её технический алгоритм ничем не отличается от предыдущей задачи.
Проверим гипотезу ![]() – о том, что генеральный коэффициент детерминации равен нулю, то есть, стоимость основных фондов вообще никак (на 0%) не влияет на суточную переработку сырья. И естественная альтернатива
– о том, что генеральный коэффициент детерминации равен нулю, то есть, стоимость основных фондов вообще никак (на 0%) не влияет на суточную переработку сырья. И естественная альтернатива ![]() , состоящая в том, что такое влияние есть.
, состоящая в том, что такое влияние есть.
Для проверки гипотезы используем случайную величину (статистический критерий) ![]() , которая имеет распределение Фишера (
, которая имеет распределение Фишера (![]() -распределение) с количеством степеней свободы
-распределение) с количеством степеней свободы ![]() .
.
Для уровня значимости ![]() и количества степеней свободы
и количества степеней свободы ![]() с помощью соответствующей функции Экселя (пункт 12) определяем критическое значение критерия:
с помощью соответствующей функции Экселя (пункт 12) определяем критическое значение критерия: ![]()
Если окажется, что наблюдаемое значение критерия ![]() (красный цвет), то гипотезу
(красный цвет), то гипотезу ![]() на уровне значимости
на уровне значимости ![]() отвергаем, если
отвергаем, если ![]() , то отвергать её – оснований нет:
, то отвергать её – оснований нет:

В нашем случае:
![]() , таким образом, на уровне значимости
, таким образом, на уровне значимости ![]() гипотезу
гипотезу ![]() отвергаем в пользу конкурирующей гипотезы
отвергаем в пользу конкурирующей гипотезы ![]() .
.
Вывод: выборочное уравнение ![]() и коэффициент детерминации
и коэффициент детерминации ![]() статически значимы. Линейная корреляционная модель подобрана удачно (для описания зависимости суточной переработки сырья от стоимости основных фондов).
статически значимы. Линейная корреляционная модель подобрана удачно (для описания зависимости суточной переработки сырья от стоимости основных фондов).
6) С помощью выборочного уравнения получим точечный прогноз суточной переработки сырья при стоимости основных фондов в ![]() млрд. руб.:
млрд. руб.:
![]() тыс. ц.
тыс. ц.
Определим доверительный интервал ![]() , который с доверительной вероятностью
, который с доверительной вероятностью ![]() накроет истинное прогнозное значение
накроет истинное прогнозное значение ![]() , полученное с помощью генерального уравнения
, полученное с помощью генерального уравнения ![]() . И, как мы выяснили, кстати, свободный член этого уравнения, с точки зрения статистики, равен нулю
. И, как мы выяснили, кстати, свободный член этого уравнения, с точки зрения статистики, равен нулю ![]() .
.
Используем формулу ![]() , где
, где ![]() – коэффициент доверия, а
– коэффициент доверия, а ![]() – стандартная ошибка точечного прогноза.
– стандартная ошибка точечного прогноза.
И этот коэффициент доверия нам уже хорошо известен из предыдущих пунктов: ![]() – для доверительной вероятности
– для доверительной вероятности ![]() и количества степеней свободы
и количества степеней свободы ![]() .
.
Стандартную ошибку точечного прогноза вычислим по формуле:
 , и здесь её нужно немного видоизменить.
, и здесь её нужно немного видоизменить.
Стандартную ошибку регрессии выразим из формулы ![]() предыдущей задачи:
предыдущей задачи: ![]() , а сумму в знаменателе – из формулы для вычисления дисперсии
, а сумму в знаменателе – из формулы для вычисления дисперсии ![]() :
:
![]() , откуда следует:
, откуда следует: 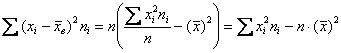
И главное тут ничего не напутать, сейчас вычислю это на калькуляторе, затем перепроверю в Экселе:
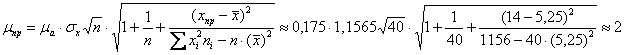
Таким образом, ![]() и искомый доверительный интервал:
и искомый доверительный интервал:
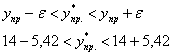
![]() – данный интервал с вероятностью
– данный интервал с вероятностью ![]() накрывает истинное генеральное прогнозное значение
накрывает истинное генеральное прогнозное значение ![]() суточной переработки сырья при стоимости основных фондов в
суточной переработки сырья при стоимости основных фондов в ![]() млрд. руб.
млрд. руб.
Готово, молодцы!
И я жду вас на следующем уроке, где мы подробно разберём математическую суть регрессионной модели.
Автор: Емелин Александр


Высшая математика для заочников и не только >>>
(Переход на главную страницу)
 © Copyright
© Copyright